Why Real-World Data Matters in Test Environments

Creating realistic test environments is crucial for software development. To understand how an application performs under pressure, developers need data that mirrors real-world conditions. This includes replicating the data patterns, volume, and variety seen in live systems.
For instance, imagine an e-commerce platform. To test new features effectively, it needs test data that mimics real customer behavior. This means data reflecting actual purchase histories, browsing patterns, and inventory changes. This need for realism, however, clashes with the need to protect sensitive production data.
This conflict often leads developers to want production data in test environments, despite the security risks. They know that synthetic data, while useful, might not capture all the nuances of real data. This is especially true for complex applications with interconnected systems, where unexpected interactions can occur. Developers aim to create test scenarios that truly reflect the customer experience, leading them to see production data as the most reliable option. This, however, introduces significant security vulnerabilities.
The Growing Complexity of Application Integration
The increasing interconnectedness of modern applications further complicates the reliance on production data in testing. As systems become more integrated, the potential impact of a security breach in a test environment grows exponentially. This interconnectedness magnifies the risk of exposing sensitive data from multiple sources, highlighting the importance of robust data management. It also makes creating realistic test data more complex, as it must accurately represent the relationships between different systems.
One key aspect of this challenge is the sheer volume of test data compared to production data. For each production environment copy, there can be 8 to 10 test data copies in development or QA. This multiplication of data copies amplifies the risk exposure and complicates data management. Developers require realistic, production-like data, especially with stricter data privacy regulations like GDPR. Synthetic data creation offers a solution, but it needs continuous refinement.
This increased focus on non-production environments stems from the understanding that these environments, vital for testing, haven’t seen much advancement lately. Finding ways to use production-like data without compromising security remains a top priority for both developers and security professionals.
The High-Stakes Security Risks You Can’t Afford to Ignore
Test environments are essential for software development. However, they often become easy targets for malicious actors. Designed for experimentation, these environments often lack the robust security of production systems. This makes them attractive to attackers looking for vulnerabilities and sensitive data. Breaches can have devastating consequences, including financial losses, reputational damage, and loss of customer trust.
Why Test Environments Are Prime Targets
Test environments often have weaker security settings compared to production systems. Access controls may be less strict, and monitoring might not be as comprehensive. This makes infiltration easier, potentially giving attackers a pathway into more secure production systems. Furthermore, test environments frequently contain copies of production data, including sensitive customer information, making them a valuable target.
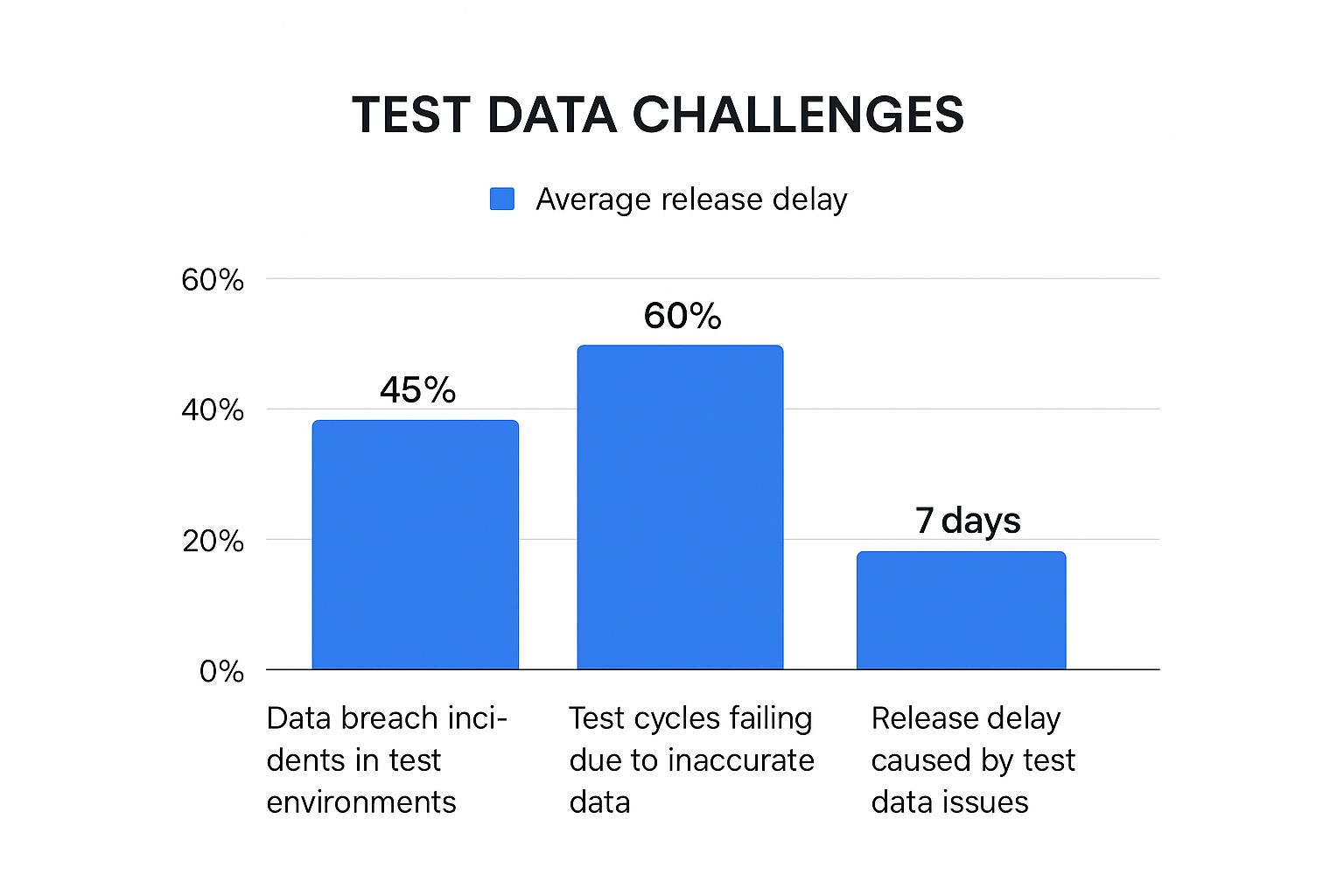
The infographic above illustrates key challenges with production data in test environments. These include data breaches, testing failures due to inaccurate data, and delayed software releases. These highlight the crucial need for effective test data management that prioritizes security and accuracy.
The Devastating Consequences of Data Breaches
Data breaches originating in test environments can be financially crippling. Beyond incident response and recovery costs, organizations may face fines, legal fees, and lasting reputational damage. Lost customer trust can lead to reduced customer loyalty and revenue loss.
Security risks linked to production data in test environments are a serious concern. A Delphix report revealed that 54% of organizations experienced breaches in lower environments. Additionally, 86% of enterprises allow data compliance exceptions in these environments, increasing the risk of sensitive data leaks. The average cost of a data breach is now $4.88 million, a 10% increase. This trend has prompted many CISOs to restrict access to production data in non-production environments, a practice expected to grow. This shift is driving the demand for synthetic data solutions. The synthetic data market, valued at $432.08 million in 2024, is projected to reach $8.87 billion by 2034. Explore this topic further.
The following table summarizes data breach statistics in test environments:
Data Breach Statistics in Test Environments
| Environment Type | Breach Percentage | Average Cost | Common Vulnerabilities |
|---|---|---|---|
| Test Environments | 54% | $4.88 million | Lax security protocols, Inadequate data controls |
| Production Environments | N/A | $4.88 million | Varied |
This table highlights the significant breach percentage in test environments compared to the overall average cost of data breaches. Common vulnerabilities stem from relaxed security measures and inadequate controls.
Real-World Breach Scenarios and Expert Insights
Many real-world cases demonstrate the vulnerability of test environments. Inadequate data controls, lax security protocols, and lack of awareness often contribute to catastrophic outcomes, damaging customer trust and company reputation. Security experts recommend a multi-layered approach to security in test environments, including robust access controls, data masking, and regular security assessments.
You might find this interesting: What is load testing software? A comprehensive guide. Understanding vulnerabilities and potential consequences empowers organizations to proactively secure their test environments. This proactive approach is crucial for protecting sensitive information, maintaining customer trust, and ensuring long-term business success.
Navigating the Regulatory Maze Without Getting Lost

Using production data in test environments has become increasingly tricky thanks to ever-changing data privacy regulations. This poses a significant challenge for development teams: How do you maintain robust testing while staying compliant? This section explores the specific requirements of major regulations like GDPR, CCPA, and HIPAA, and how they affect your test data management.
Understanding the Impact of GDPR, CCPA, and HIPAA
These regulations have significantly altered how organizations must handle personal data, including data used for testing. GDPR (General Data Protection Regulation) emphasizes data minimization and purpose limitation. This means organizations must justify using any personal data, even in testing.
Similarly, CCPA (California Consumer Privacy Act) gives consumers broad rights regarding their data. This affects how businesses collect, use, and share data, even during internal testing. HIPAA (Health Insurance Portability and Accountability Act) sets strict rules for protecting health information. This makes using production data in test environments especially difficult for healthcare organizations.
For example, under GDPR, using production data in testing requires a clear legal basis, such as explicit consent or legitimate interest. This necessitates robust data governance frameworks. CCPA’s focus on consumer control means organizations must be transparent about how they’re using test data and provide opt-out mechanisms when appropriate. This transparency necessitates meticulous documentation and communication. For organizations covered by HIPAA, de-identification or anonymization of protected health information is often required before using it in testing. This necessitates specialized tools and procedures.
Building a Compliant Governance Framework
Smart organizations are building comprehensive governance frameworks to meet these regulatory challenges. These frameworks lay out clear policies and procedures for managing production data in test environments. They include data sensitivity assessments, role-based access controls, and regular audits to ensure compliance and maintain developer productivity.
- Data Sensitivity Assessments: Classify data according to its sensitivity.
- Role-Based Access Controls: Restrict access based on job roles and responsibilities.
- Regular Audits: Conduct regular audits of test data practices to ensure ongoing compliance.
These measures guarantee that only authorized personnel have access to necessary data, minimizing the risk of unauthorized exposure and providing a clear audit trail for demonstrating compliance to regulators.
Practical Implementation and Cross-Functional Alignment
Putting these frameworks into practice requires teamwork. Security, legal, and development teams need to collaborate on clear guidelines, define responsibilities, and ensure consistent enforcement. Documenting compliance efforts is crucial for creating a defensible audit trail.
Organizations also need strategies for adapting to evolving regulations across different jurisdictions. This often means implementing flexible data management processes that can be easily adjusted as regulations change, minimizing disruptions to testing workflows. By proactively addressing regulatory requirements, organizations can confidently use production data in test environments, protect sensitive information, and maintain customer trust.
Modern Test Data Management: Beyond the Basics

Traditional methods of managing production data in test environments often come with significant shortcomings. Directly copying production databases introduces considerable security and compliance risks. This highlights the need for robust Test Data Management (TDM) practices. These modern approaches are changing how companies balance realistic test data with the crucial need for data protection.
Intelligent Data Subsetting and Virtualization
A significant advancement in TDM is intelligent data subsetting. This method focuses on selecting only the data required for specific tests, minimizing the amount of sensitive information involved. Virtualization techniques create efficient, on-demand copies of production data. This reduces storage expenses and speeds up testing cycles.
Consider a bank testing a new loan application. Instead of copying the entire customer database, they can subset only the data relevant to loan applications. Virtualization allows testers to access this subset rapidly without managing numerous physical copies. This leads to increased agility and efficiency in testing.
For a deeper dive into performance testing strategies, check out this guide: Performance Testing Strategy: A Complete Guide for Modern Apps.
Real-World Implementation Stories and Measurable Improvements
Many companies are already experiencing significant advantages from implementing modern TDM solutions. These benefits include faster testing, lower storage costs, stronger compliance, and improved testing quality. Adopting these technologies allows companies to become more efficient, reduce risks, and accelerate their software development life cycles. These advancements also improve testing accuracy, allowing for earlier detection and correction of defects.
The following table summarizes different TDM approaches:
To understand the various approaches to Test Data Management, let’s look at a comparison:
Comparison of Test Data Management Approaches Analysis of different methods for handling production data in test environments
| Approach | Security Level | Data Fidelity | Implementation Complexity | Cost Considerations | Regulatory Compliance |
|---|---|---|---|---|---|
| Full Copy | Low | High | Low | High | Difficult |
| Data Subsetting | Medium | Medium | Medium | Medium | Easier |
| Data Masking | High | Medium | High | Medium | Easier |
| Synthetic Data Generation | High | Low | High | Low | Easiest |
| Virtualization | High | High | Medium | Low | Easier |
As you can see, each approach offers a different balance of security, fidelity, and cost. Choosing the right approach depends on your specific needs and risk tolerance.
The Test Data Management (TDM) market is growing rapidly, demonstrating the increasing importance of managing production data in test environments. Currently valued at $1,119.22 million, the TDM market is projected to reach $2,561.25 million by 2032, with a CAGR of approximately 12%. This growth is driven by the increasing complexity of IT systems, growing data governance requirements, and the demand for efficient and compliant testing. For detailed statistics, see Custom Market Insights.
Emerging Trends: AI, DevOps, and Cloud-Native Approaches
Several key trends are shaping the future of TDM. AI-powered anomaly detection automatically identifies and flags unusual data patterns in test environments, improving security. Seamless DevOps integration automates TDM processes and aligns them with the overall development workflow. Cloud-native approaches offer increased flexibility and scalability for managing test data in cloud environments.
These innovations are not just about increasing efficiency. They empower companies to build more secure, reliable, and compliant testing practices. By adopting these advancements, companies can revolutionize their approach to TDM and fully leverage their test data without compromising security or compliance.
Synthetic Data: Creating Reality Without the Risk
Synthetic data is quickly changing how top organizations approach testing with production data in test environments. It’s more than just a security measure; it’s a way to build realistic testing scenarios without the dangers of using real production data. This change is fueled by the need for better security, stricter privacy rules, and the growing complexity of modern applications.
How Synthetic Data Generation Works
Modern generation algorithms can create statistically accurate synthetic datasets. These datasets keep the complex relationships within the original data, but without revealing any sensitive information. This is vital for effectively testing software in environments that mirror real-world situations. The algorithms learn the patterns and structures in the production data and then generate new data that reflects those characteristics.
For example, imagine testing a new feature on an e-commerce site. Synthetic data can create realistic customer purchase histories, browsing patterns, and inventory changes. This lets developers thoroughly test the new feature under conditions similar to a live environment, without using any real customer data.
Advantages of Synthetic Data Over Traditional Masking
Traditional data masking techniques offer a certain degree of protection. However, synthetic data goes further in several important aspects. Masking simply hides sensitive data elements. Synthetic data, on the other hand, builds entirely new data points. This completely removes the risk of exposing real user information.
Furthermore, synthetic data allows for testing scenarios that wouldn’t be possible with masked production data or even subsets of it. You can generate synthetic data to simulate unusual cases or rare events that might not be in your production data. This results in more comprehensive testing and potentially finding serious bugs earlier in the development process.
Implementing Synthetic Data: Challenges and Solutions
Synthetic data brings substantial benefits, but there are practical challenges in putting it to use. A key challenge is ensuring the fidelity of the synthetic data. It must accurately reflect the real-world patterns and relationships in your production data. This demands careful validation and fine-tuning of the generation algorithms.
Another challenge lies in meeting the specific data needs of different data types. Generating synthetic data for transactional records is quite different from creating synthetic customer journeys. Each requires particular techniques and tools.
- Transactional Data: Needs algorithms that focus on numerical relationships and patterns.
- Customer Journeys: Needs algorithms that can recreate complex sequences of events.
Validation strategies are crucial to confirm your synthetic data properly represents production patterns while maintaining privacy. GoReplay can then use this validated synthetic data to replay realistic traffic patterns in your test environment. This allows for accurate load testing and performance validation without resorting to production data.
By understanding and tackling these challenges, organizations can effectively implement synthetic data solutions. This creates more robust and secure test environments, protecting sensitive information and boosting software quality.
Building Your Production Data Strategy That Actually Works
A well-defined strategy for using production data in test environments is crucial for balancing realistic testing with security and compliance. This section outlines practical steps for building a robust strategy that works, focusing on clear governance, effective controls, and a culture of security.
Conducting Data Sensitivity Assessments
Understanding your data is the first step. A data sensitivity assessment categorizes data based on its sensitivity, determining the appropriate protection level. This involves identifying all test data, classifying it based on regulations and internal policies, and assigning appropriate security measures.
For example, personally identifiable information (PII) like names and addresses requires higher protection than aggregated sales data. This prioritizes security efforts and allocates resources effectively. Regularly review and update this assessment to reflect evolving regulations and data changes.
Establishing Role-Based Access Controls
Controlling access to production data in test environments is paramount. Role-based access controls (RBAC) restrict access based on individual roles and responsibilities. Developers access only the data needed for their tasks, limiting potential exposure.
This principle of least privilege minimizes unauthorized access and data breaches. RBAC requires careful planning to ensure efficient access without hindering productivity. For instance, a tester working on a payment feature might need access to transaction data but not customer PII.
Implementing Monitoring Systems and Data Masking Techniques
Detecting and responding to data misuse is essential. Implement robust monitoring systems that track data access and usage patterns. This provides visibility into data usage and allows for quick identification of suspicious activities. Avoid “alert fatigue” by focusing on actionable alerts. This monitoring should cover data access, modifications, and deletions.
Data masking techniques, like anonymization and pseudonymization, further protect sensitive data. These techniques make data unusable for unauthorized purposes while preserving its utility for testing. Monitoring systems can alert teams to unusual access patterns. Data masking ensures that even if a breach occurs, the exposed data is useless.
Data Subsetting and Change Management
Effective data subsetting involves selecting only the necessary data for specific tests. This reduces sensitive data in the test environment and simplifies management. Maintain referential integrity within the subset to ensure accurate test results. This preserves relationships between data elements, reflecting the production data structure.
A successful strategy requires careful change management. This includes communicating policy changes, training staff on new techniques, and ensuring everyone understands their responsibilities. Change management fosters a culture of security and ensures best practice adoption.
Implementation Timelines and Resource Requirements
Implementation requires time, resources, and commitment. Different organizations will have varying timelines and requirements. Smaller organizations with simpler infrastructures might implement quickly. Larger enterprises with complex systems may require more time.
| Maturity Level | Implementation Timeline | Resource Requirements |
|---|---|---|
| Basic | 3-6 months | Low |
| Intermediate | 6-12 months | Medium |
| Advanced | 12+ months | High |
By following these steps, organizations build a robust strategy for test environments, ensuring realistic testing while protecting information and complying with regulations. This empowers development teams to work efficiently, accelerating the software development lifecycle and reducing breach risks.
Ready to enhance your testing with real-world traffic, while prioritizing security? Explore GoReplay and transform your testing environments.