8 Best Practices for Microservices to Master in 2025
The shift from monolithic architectures to microservices represents a significant evolution in software development. While the promise of improved agility, scalability, and independent deployment is compelling, navigating this distributed landscape requires a deliberate and strategic approach. Without a solid foundation of proven principles, teams risk building a “distributed monolith,” a system that combines the complexity of microservices with the tight coupling and deployment challenges of a monolith. This architectural anti-pattern negates the very benefits sought from microservices in the first place.
This guide cuts through the noise to deliver a curated list of the most critical best practices for microservices. We will explore eight essential patterns and strategies that form the bedrock of successful distributed systems. By focusing on these core tenets, you can avoid common pitfalls and build a system that is both resilient and maintainable.
Readers will gain actionable insights into:
- Foundational Design: Defining clear service boundaries using Domain-Driven Design (DDD) and managing data with the Database per Service pattern.
- Resilient Communication: Implementing API Gateways for streamlined access and the Circuit Breaker pattern for fault tolerance.
- Operational Excellence: Leveraging containerization, automated CI/CD pipelines, and comprehensive observability for monitoring and health checks.
- Robust Testing: Building an automated testing strategy, including advanced techniques like traffic replay, to ensure reliability under real-world conditions.
Each practice detailed here is a crucial pillar supporting a high-performing microservices ecosystem. Mastering these concepts will equip your team with the tools needed to design, deploy, and maintain scalable applications effectively.
1. Domain-Driven Design (DDD) for Service Boundaries
One of the most critical challenges in a microservices architecture is deciding where to draw the lines between services. Making the wrong cuts can lead to a distributed monolith, a system with high coupling and low cohesion that negates the benefits of the microservices pattern. Domain-Driven Design (DDD) offers a strategic blueprint to avoid this pitfall, making it one of the foundational best practices for microservices. DDD shifts the focus from technical layers to the core business domain.
At its heart, DDD is an approach to software development that centers on modeling the software to match a specific business domain. It aligns the technical architecture with the business structure, ensuring that each microservice represents a distinct and cohesive business capability. This is achieved by identifying Bounded Contexts, which are explicit boundaries within which a particular domain model is consistent and well-defined. For example, in an e-commerce system, “Inventory Management” and “Order Processing” are separate Bounded Contexts, each with its own language, logic, and data.
Key Concepts in DDD
- Bounded Context: This is the most crucial concept. It defines the boundary of a microservice. Inside this context, every term and concept has a specific, unambiguous meaning.
- Ubiquitous Language: A common, shared language developed by developers and domain experts to talk about the system. This language is used in all communication, code, and documentation related to the bounded context, eliminating ambiguity.
- Aggregates: A cluster of associated domain objects that can be treated as a single unit. An aggregate has a root entity, and all external access must go through this root, ensuring the integrity and consistency of the objects within it.
The following concept map illustrates how Bounded Contexts create the necessary structure for a robust microservice architecture.
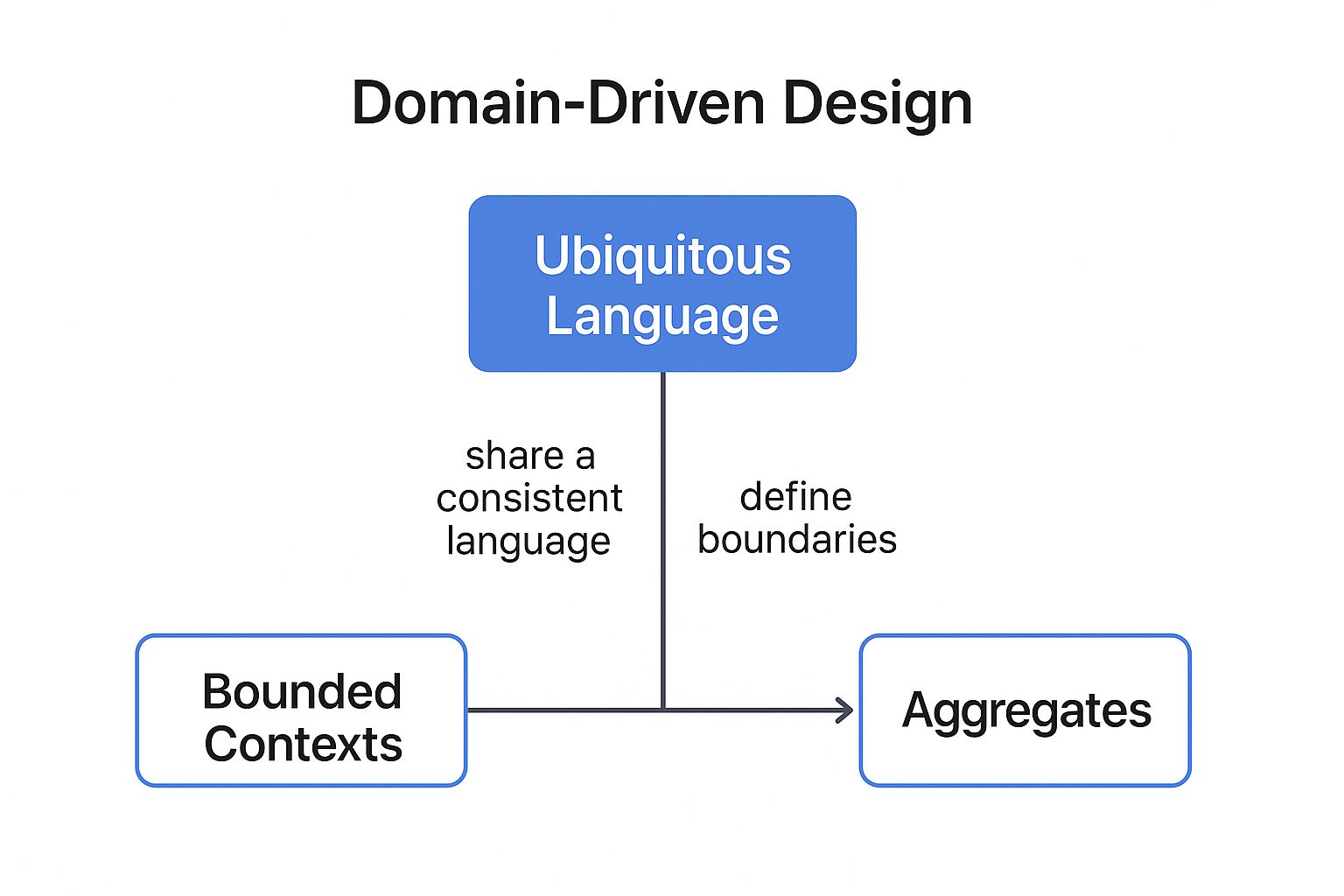
As the infographic shows, the Bounded Context is the central organizing principle that defines the scope for both the Aggregates (the data and entities) and the Ubiquitous Language (the team’s shared vocabulary).
Actionable Tips for Implementation
To apply DDD effectively, start with collaborative workshops like Event Storming. These sessions bring developers, product managers, and business stakeholders together to map out business processes and identify key events, commands, and domains. This process naturally reveals the boundaries for your services.
Key Insight: Don’t aim for micro-perfection from day one. It’s often better to start with slightly larger, more coarse-grained services (macroservices) and decompose them further as your understanding of the domain deepens.
For a deeper dive into DDD concepts, Vaughn Vernon provides a comprehensive overview:
2. API Gateway Pattern
In a microservices architecture, clients would traditionally need to make requests to multiple different services to perform a single operation. This approach creates tight coupling between the client and the backend services, complicates client-side code, and introduces security and management challenges. The API Gateway Pattern solves this by providing a single, unified entry point for all client requests, making it a cornerstone among best practices for microservices. It acts as a reverse proxy, routing requests to the appropriate downstream service.
This pattern decouples clients from the internal service structure, allowing services to evolve independently without breaking client applications. The gateway is the ideal place to handle cross-cutting concerns that would otherwise need to be duplicated in every service. This includes tasks like authentication and authorization, rate limiting, logging, and response caching. For example, instead of each microservice implementing its own SSL termination and authentication logic, the API Gateway can handle it once for all incoming traffic.

As the diagram illustrates, all client requests (from web, mobile, or other devices) are first directed to the API Gateway. The gateway then intelligently routes these requests to the corresponding internal microservices, such as Product, Order, or User services, while handling shared responsibilities.
Key Concepts in API Gateway Pattern
- Request Routing: The primary function of the gateway. It maps incoming external requests to the correct internal microservice based on URL paths, headers, or other criteria.
- Request Aggregation: The gateway can compose a single client request into multiple calls to different microservices and then aggregate the results into a single response. This simplifies the client’s interaction, reducing the number of round trips.
- Cross-Cutting Concerns: Centralizes functionalities like security (authentication, authorization), rate limiting, monitoring, logging, and caching, keeping the microservices themselves lean and focused on business logic.
Actionable Tips for Implementation
To implement an API Gateway effectively, choose a solution that fits your ecosystem, such as Amazon API Gateway for AWS-native applications or open-source options like Kong. Start by identifying common, repetitive tasks that can be offloaded from your services. Implement robust monitoring on the gateway itself to track latency, error rates, and traffic volume, as it can become a performance bottleneck if not managed carefully.
Key Insight: Keep the logic within the API Gateway as simple as possible. It should primarily focus on routing and cross-cutting concerns. Avoid embedding complex business logic, as this can turn the gateway into a new monolith and a single point of failure.
For more on this pattern, Chris Richardson offers a foundational overview:
3. Database per Service Pattern
A core principle of microservice autonomy is data independence, and the Database per Service pattern is the key mechanism to achieve it. In this model, each microservice exclusively owns and manages its own database. No other service is allowed to directly access this database, ensuring that the service’s data is completely encapsulated. This is one of the most fundamental best practices for microservices because it enforces loose coupling at the persistence layer.
This approach prevents the creation of a distributed monolith, where services are technically separate but are all tethered to a single, shared database. By giving each service its own data store, you empower individual teams to choose the best database technology for their specific needs. For instance, a user profile service might use a document database like MongoDB for flexibility, while a financial transaction service could use a relational database like PostgreSQL for ACID compliance. Companies like Netflix and Amazon have famously used this pattern to scale their massive, distributed systems.
Key Concepts in the Database per Service Pattern
- Data Encapsulation: The service’s data is hidden and can only be accessed through its public API. This prevents other services from creating unintended and brittle dependencies on its internal data schema.
- Service Autonomy: Since each service controls its own data, teams can deploy, scale, and evolve their service and its schema independently, without coordinating with or breaking other teams.
- Polyglot Persistence: Teams are free to select the database technology that is the best fit for their service’s requirements, rather than being forced into a one-size-fits-all solution.
This pattern directly supports the core benefits of a microservices architecture: improved scalability, fault isolation, and enhanced developer productivity by enabling independent team workflows.
Actionable Tips for Implementation
To implement this pattern without sacrificing data consistency across the system, you must adopt new strategies for managing data. Direct database queries between services are forbidden, so you must rely on API calls or asynchronous communication.
Key Insight: Adopting the Database per Service pattern means you must also embrace patterns for managing distributed transactions and data consistency, such as Sagas and event-driven architecture.
For a deeper understanding of distributed transaction management, which is essential when using this pattern, consider the Saga pattern explained here:
4. Circuit Breaker Pattern
In a distributed system, network failures and service unavailability are inevitable. A single slow or failing service can trigger a cascade of failures across dependent services, leading to a complete system outage. The Circuit Breaker pattern is a critical design mechanism that prevents this scenario, making it one of the essential best practices for microservices. It acts as a proxy for operations that might fail, monitoring for failures and tripping to stop repeated calls to an unhealthy service.
Popularized by Michael Nygard in his book Release It! and famously implemented in libraries like Netflix’s Hystrix, the pattern operates like an electrical circuit breaker. It starts in a Closed state, allowing all requests to pass through. If the number of failures exceeds a configured threshold within a specific time window, the breaker trips to an Open state. In this state, it immediately rejects subsequent requests without attempting to contact the failing service, preventing resource exhaustion and allowing the downstream service time to recover. After a timeout period, the breaker moves to a Half-Open state, where it allows a limited number of test requests to see if the service has recovered. Success closes the circuit, while failure keeps it open.

This state machine gracefully handles transient faults, improves system resilience, and ensures that one failing component doesn’t bring down the entire application. It’s a cornerstone of building robust, fault-tolerant microservices architectures used by companies like Amazon and Uber to protect their vast service ecosystems.
Actionable Tips for Implementation
To implement the Circuit Breaker pattern effectively, you need more than just a library; you need a strategy. Modern service meshes like Istio or Linkerd often provide this functionality out-of-the-box, but a deep understanding is still crucial for proper configuration.
- Set Appropriate Thresholds: Configure failure thresholds and timeouts based on the specific service’s SLA and typical response times. A one-size-fits-all approach can cause premature tripping or delayed detection.
- Implement Meaningful Fallbacks: When a circuit is open, don’t just return an error. Provide a graceful fallback response, such as returning cached data, default values, or queuing the request for later processing.
- Monitor and Alert: Track the state of your circuit breakers. Set up alerts for when circuits open, so your team is immediately aware of service degradation.
- Combine with Bulkheads: Use the Bulkhead pattern alongside circuit breakers to isolate resources (like connection pools or thread pools) for each dependency, preventing one failing service from consuming all resources.
Key Insight: Always test your circuit breaker configurations in a staging or pre-production environment. Use fault injection testing to simulate service failures and verify that the breakers trip as expected and that fallback logic works correctly.
Martin Fowler provides an excellent in-depth explanation of the pattern on his blog:
https://martinfowler.com/bliki/CircuitBreaker.html
5. Asynchronous Communication with Event-Driven Architecture
In a distributed system, direct, synchronous communication between services can create tight coupling and cascading failures. If one service is slow or unavailable, all services calling it are impacted, leading to poor resilience. Adopting an event-driven architecture (EDA) with asynchronous communication is a superior approach and a cornerstone of effective best practices for microservices. This pattern decouples services, allowing them to interact without direct knowledge of one another.
At its core, EDA involves services publishing events when something significant happens, like a user placing an order. Other services interested in that event can subscribe and react accordingly, such as an inventory service decrementing stock or a notification service sending an email. This “fire-and-forget” model creates a more scalable and resilient system. For example, Uber’s dynamic surge pricing and Netflix’s real-time content recommendations are both powered by sophisticated event-driven systems that can process millions of events per second.
Key Concepts in EDA
- Event: A record of a significant change in state. For example,
OrderCreatedorPaymentProcessed. - Publisher: A service that creates and sends an event to a message broker. It has no knowledge of the consumers.
- Subscriber (or Consumer): A service that listens for specific events and processes them. It is decoupled from the publisher.
- Message Broker: An intermediary component (like Apache Kafka or RabbitMQ) that receives events from publishers and routes them to interested subscribers.
This decoupled model ensures that the failure of one consumer service does not impact the publisher or other consumers, dramatically improving system fault tolerance.
Actionable Tips for Implementation
- Use a Robust Message Broker: Choose a broker like Apache Kafka for high-throughput streaming or RabbitMQ for complex routing and guaranteed delivery based on your specific needs.
- Implement Event Schemas and Versioning: Define a clear structure for your events using a schema registry (like Confluent Schema Registry). This prevents breaking changes when event structures evolve over time.
- Design for Idempotency: Ensure that processing the same event multiple times has no additional effect. Network issues can cause duplicate message delivery, and idempotent consumers prevent data corruption.
- Implement Dead Letter Queues (DLQ): Route messages that fail to be processed after several retries to a DLQ. This prevents poison pills from blocking the main queue and allows for later analysis and manual intervention.
Key Insight: Don’t just broadcast state changes. Events should represent meaningful business occurrences. An
OrderUpdatedevent is less useful than specific events likeOrderShippedorOrderCancelled, which convey clear business intent.
For a comprehensive guide on building event-driven systems, Martin Fowler’s articles offer invaluable patterns and insights.
6. Comprehensive Monitoring and Observability
In a monolithic application, debugging is relatively straightforward. In a microservices architecture, a single user request can traverse dozens of services, making it incredibly difficult to pinpoint the source of an error or a performance bottleneck. This distributed complexity makes comprehensive monitoring and observability one of the most essential best practices for microservices. It’s not just about knowing if a service is up or down; it’s about understanding the end-to-end behavior of the entire system.
Observability provides deep insights into your system’s state from its external outputs, allowing you to ask arbitrary questions about its behavior without needing to ship new code. It moves beyond simple, predefined dashboards to enable dynamic, exploratory debugging. For instance, companies like Netflix and Uber have built their entire operational culture around robust observability platforms, enabling them to maintain reliability across thousands of services.
The Three Pillars of Observability
A mature observability strategy is built on three core data types, often called the “three pillars,” that work together to provide a complete picture of system health.
- Metrics: Time-series numerical data that represents system health and performance over time (e.g., CPU usage, latency, error rates). They are ideal for dashboards and alerting on known failure modes.
- Logs: Timestamped, immutable records of discrete events. Logs provide granular, context-rich details about what happened at a specific point in time within a single service.
- Traces: A representation of a single request’s journey as it moves through all the different services in the system. Traces are crucial for visualizing request flows and identifying performance bottlenecks in a distributed environment.
Actionable Tips for Implementation
To build an effective observability practice, focus on unifying these data sources. Start by implementing health check endpoints (/health or /status) for every service so that orchestrators can automatically manage service health. Most importantly, ensure you can connect the dots between the pillars.
Key Insight: Use a correlation ID for every incoming request at the edge of your system. Propagate this ID across all subsequent service calls, and include it in every log and trace. This allows you to filter logs and traces for a single, specific request, transforming a complex debugging task into a manageable one.
For a more detailed breakdown of implementation strategies, you can read this essential guide to API monitoring. This resource provides practical steps for setting up the necessary telemetry to achieve true system visibility.
7. Containerization and Orchestration
Once microservices are built, they need to be deployed, managed, and scaled efficiently. This is where containerization and orchestration become indispensable best practices for microservices. This two-part strategy involves packaging each service into a lightweight, portable container and then using an orchestration platform to manage the lifecycle of these containers automatically. This approach decouples services from the underlying infrastructure, ensuring consistency across development, testing, and production environments.
The combination of containerization (using tools like Docker) and orchestration (with platforms like Kubernetes) provides a powerful foundation for a resilient and scalable microservices architecture. Containers bundle an application’s code with all its dependencies, guaranteeing that it runs the same way everywhere. Orchestrators then handle complex tasks like deployment, scaling, load balancing, and self-healing, freeing up development teams to focus on building business value rather than managing infrastructure. For instance, Netflix developed its own container orchestrator, Titus, to manage its massive-scale infrastructure, while companies like Spotify and Airbnb have built their platforms on Kubernetes.
Key Concepts in Containerization and Orchestration
- Container: A standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
- Container Image: A lightweight, standalone, executable package that includes everything needed to run a piece of software, including the code, runtime, system tools, libraries, and settings.
- Orchestration: The automated configuration, coordination, and management of containerized applications. It handles service discovery, load balancing, resource allocation, and scaling.
- Pod (in Kubernetes): The smallest deployable unit in Kubernetes, representing a single instance of a running process. A Pod encapsulates one or more containers, storage resources, and a unique network IP.
The synergy between these concepts enables a dynamic and robust operational model, where services can be scaled up or down in seconds in response to demand.
Actionable Tips for Implementation
To harness the full power of this approach, focus on optimizing your container and cluster configurations from the start.
- Use multi-stage Docker builds: Create smaller, more secure production images by separating build-time dependencies from the final runtime image.
- Implement resource limits and requests: Define CPU and memory requests and limits for your containers to ensure predictable performance and prevent any single service from starving others of resources.
- Leverage ConfigMaps and Secrets: Externalize configuration from your application code. Use ConfigMaps for non-sensitive data and Secrets for credentials, tokens, and keys.
- Configure health checks: Implement readiness and liveness probes to help the orchestrator know if your service is ready to receive traffic or needs to be restarted, improving system reliability.
Key Insight: Don’t treat your orchestration platform as just a deployment tool. Explore advanced features like service meshes (e.g., Istio, Linkerd) for sophisticated traffic management, observability, and security controls without altering your application code.
For a foundational understanding of Kubernetes, the official documentation from the Cloud Native Computing Foundation (CNCF) is an excellent resource.
8. Automated Testing Strategy
In a distributed system, the risk of failure shifts from a single monolithic application to the complex interactions between services. A robust automated testing strategy is therefore not just a good idea; it is one of the most essential best practices for microservices. Without it, you cannot confidently deploy changes, as a small modification in one service could have cascading, unpredictable effects across the entire system. A comprehensive strategy moves beyond simple unit tests to validate the contracts, integrations, and end-to-end flows that define your architecture.
An effective microservices testing approach involves a layered strategy, often visualized as the test pyramid. It ensures that while each service is reliable in isolation, the system as a whole functions correctly. Companies like Netflix and Spotify have pioneered advanced testing methodologies, integrating everything from contract testing to chaos engineering directly into their CI/CD pipelines. This allows them to deploy thousands of times per day with high confidence, validating service reliability and the integrity of service interactions automatically.
Key Concepts in Microservices Testing
- Unit Tests: These form the base of the pyramid, verifying the logic within a single service without external dependencies. They are fast, cheap to run, and provide immediate feedback.
- Integration Tests: These check the interaction points of a service, such as its communication with a database, message queue, or other services. Service virtualization is often used here to isolate the service under test.
- Contract Tests: A critical component for microservices, contract tests verify that a service (the “provider”) honors the expectations of its consumer. Consumer-Driven Contract Testing (using tools like Pact) ensures that changes in a provider service don’t break its downstream consumers.
- End-to-End (E2E) Tests: These tests simulate a full user journey across multiple services to validate the entire workflow. They are valuable but should be used sparingly as they are slow, brittle, and expensive to maintain.
Actionable Tips for Implementation
To build a resilient testing pipeline, focus on automating at every level. Start by ensuring high unit test coverage, then layer in contract and integration tests to secure service boundaries. Use service virtualization to mock dependencies, allowing services to be tested independently and reliably. Finally, incorporate performance testing and a minimal suite of E2E tests into your deployment process to catch system-level issues.
Key Insight: Shift your focus from extensive end-to-end testing to robust consumer-driven contract testing. Contract tests provide high confidence in service integrations without the brittleness and high maintenance cost of traditional E2E test suites.
For organizations looking to build out their testing capabilities, it’s crucial to understand the available tools and techniques. You can explore a variety of methods for building a strong pipeline in this guide on Automated Testing Strategy.
Best Practices Comparison Matrix
| Pattern / Practice | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Domain-Driven Design (DDD) for Service Boundaries | High – requires deep domain knowledge and collaboration | Moderate – involves domain experts and modeling | Clear service boundaries, reduced coupling | Decomposing monoliths into business-aligned microservices | Aligns tech with business, improves maintainability and scaling |
| API Gateway Pattern | Medium – introduces additional architectural layer | Moderate – gateway infrastructure and config | Simplified client interactions, centralized cross-cutting | Managing client requests in microservices architectures | Centralizes security, routing, API versioning |
| Database per Service Pattern | Medium – managing multiple independent databases | High – more databases and operations overhead | Service autonomy, loose coupling of data stores | Microservices needing independent data storage and choices | Enables database flexibility and failure isolation |
| Circuit Breaker Pattern | Low to Medium – requires designing failure handling | Low – implemented in service communication | Improved fault tolerance and system resilience | Handling unstable or unreliable service calls | Prevents cascading failures, fast failure detection |
| Asynchronous Communication with Event-Driven Architecture | High – complex event management and consistency | High – messaging infrastructure and tooling | Loose coupling, better scalability and fault tolerance | Systems requiring decoupled, scalable workflows | Supports complex workflows and system evolution |
| Comprehensive Monitoring and Observability | Medium to High – requires instrumentation and aggregation | High – monitoring infrastructure and tooling | Rapid issue detection, system visibility and insights | Production microservices needing reliability and diagnostics | Enables data-driven decisions and compliance support |
| Containerization and Orchestration | Medium to High – learning and managing containers/orchestration | Moderate to High – container runtime and orchestrator resources | Consistent deployments, simplified scaling | Deploying and managing microservices at scale | Infrastructure abstraction, efficient resource use |
| Automated Testing Strategy | High – broad test types and CI/CD integration | Moderate to High – test tools, environments, and frameworks | High reliability, faster issue detection | Ensuring quality in distributed microservices | Supports rapid development with confidence and documentation |
Building Resilient Systems with Purposeful Practices
Navigating the transition to a microservices architecture is a journey from monolithic predictability to distributed dynamism. It represents a fundamental shift in how we design, build, and operate software. As we have explored, this journey is not about adopting a trendy architectural style; it’s about making a deliberate commitment to a set of principles that foster resilience, scalability, and organizational agility. The “best practices for microservices” detailed in this guide are not isolated checklist items but interconnected pillars supporting a robust, modern software ecosystem.
Success in this paradigm hinges on moving beyond the “what” and deeply understanding the “why” behind each practice. It’s about recognizing that the true power of microservices is unlocked only when these concepts are applied in concert, forming a cohesive strategy that addresses the inherent complexities of distributed systems.
From Theory to Tangible Results: A Recap of Key Strategies
The eight practices we’ve detailed provide a comprehensive roadmap. Let’s briefly revisit how they work together to create a resilient and efficient architecture:
-
Strategic Design (DDD & API Gateway): We started with the foundation. Domain-Driven Design (DDD) ensures your services are logically coherent and aligned with business realities, preventing the creation of a distributed monolith. The API Gateway pattern then provides a unified, secure, and manageable entry point, simplifying client interactions and protecting your internal services.
-
Data and Communication (Database per Service & EDA): We then addressed the flow of information. The Database per Service pattern is non-negotiable for true service independence, eliminating data contention and enabling autonomous scaling. Event-Driven Architecture (EDA) complements this by facilitating asynchronous, non-blocking communication, which builds a loosely coupled system that is inherently more resilient to individual service failures.
-
Operational Excellence (Observability & Containerization): To manage this distributed landscape, you need superior visibility and control. Comprehensive Observability (logs, metrics, traces) is your nervous system, allowing you to understand behavior and diagnose issues in a complex environment. Containerization and Orchestration (like Docker and Kubernetes) provide the standardized, automated, and scalable infrastructure needed to deploy and manage these services efficiently.
-
Resilience and Confidence (Circuit Breakers & Automated Testing): Finally, we focused on building systems that can withstand failure. The Circuit Breaker pattern is a critical defense mechanism, preventing cascading failures and allowing your system to degrade gracefully. This is supported by a robust Automated Testing Strategy, where techniques like traffic shadowing with tools like GoReplay provide the ultimate confidence by validating changes against real-world production traffic without risk.
Your Path Forward: Implementing Microservices Best Practices
Embracing these best practices for microservices is not an all-or-nothing proposition. It is an iterative process of maturation. As you move forward, consider these actionable next steps:
- Assess Your Current State: Where does your team stand? Are your service boundaries unclear? Is your testing strategy lagging behind your deployment velocity? Identify the one or two areas that present the most significant challenges and start there.
- Foster a Culture of Ownership: Microservices thrive in environments where small, empowered teams own their services end-to-end, from code to production. Champion this cultural shift alongside your technical implementations.
- Invest in Tooling: The right tools are force multipliers. Whether it’s an observability platform, a service mesh, or a traffic replay tool, investing in your team’s toolchain pays dividends in productivity and system reliability.
The journey toward microservices mastery is challenging, but the rewards are substantial. It empowers teams to innovate faster, scale systems with confidence, and build applications that are not just functional but truly resilient. By treating these practices as a holistic framework rather than a menu of options, you position your organization to harness the full transformative power of this architectural approach, building the adaptable, high-performing systems that modern business demands.
Ready to bulletproof your testing strategy? GoReplay helps you implement one of the most powerful best practices for microservices by safely capturing and replaying your production traffic to your staging or development environments. Validate performance, catch breaking changes, and deploy with confidence by visiting the GoReplay website to see how traffic shadowing can transform your QA process.