The Art and Science of Stress vs. Load Testing

Stress and load testing are essential for ensuring any application’s resilience and stability. However, their distinct purposes often lead to confusion. This section clarifies the key differences and underscores the importance of both in a comprehensive testing strategy. By understanding these differences, teams can effectively identify and address vulnerabilities before they impact users.
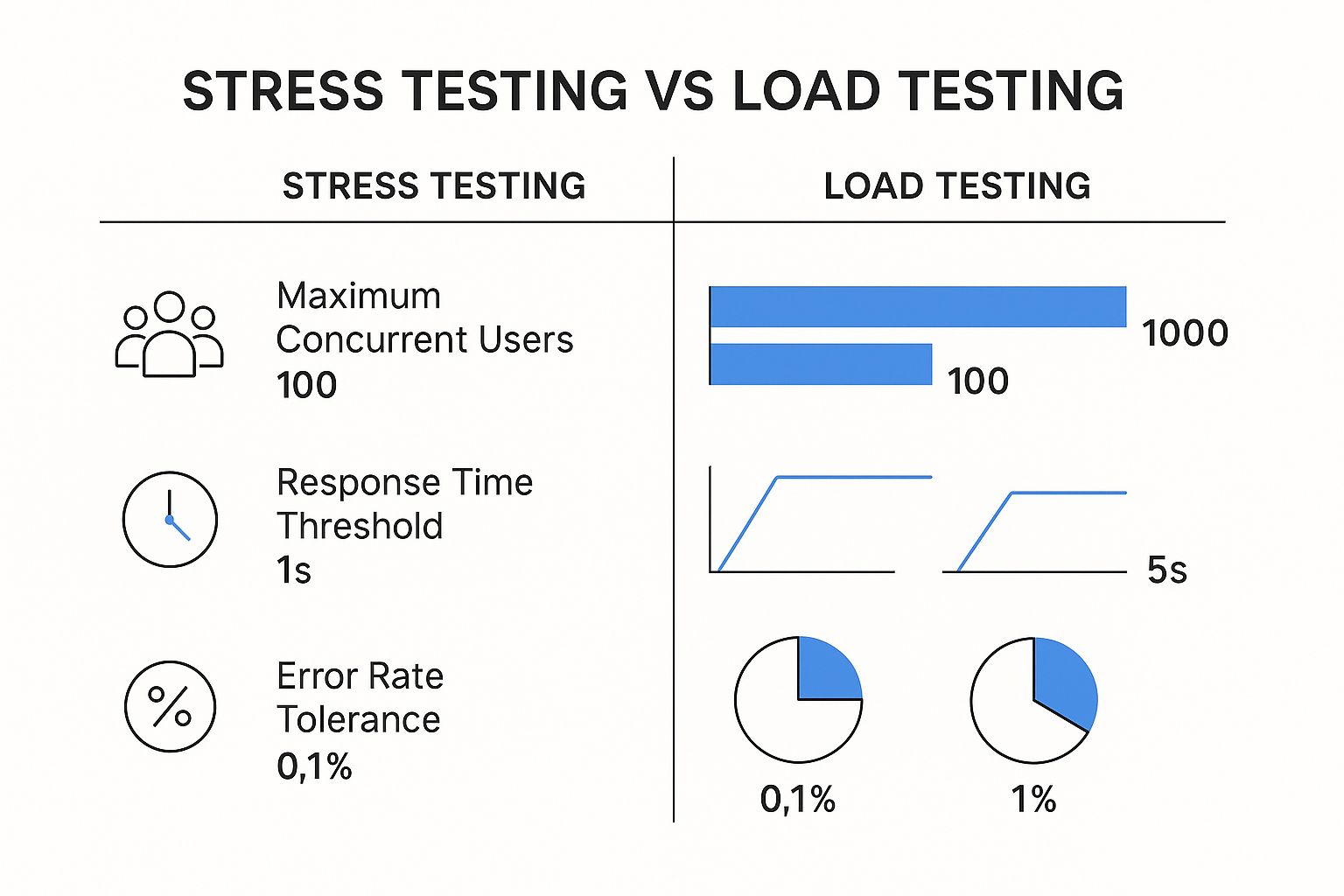
Understanding Load Testing
Load testing evaluates how a system performs under expected conditions. This involves simulating real-world user traffic to assess the application’s behavior under normal usage. For instance, if a website anticipates 1,000 concurrent users, a load test would simulate this traffic.
This helps measure key metrics like response times, resource utilization, and error rates. The main goal is to ensure the application meets its performance requirements under the anticipated load.
Delving into Stress Testing
Unlike load testing, stress testing pushes a system beyond its limits to identify its breaking points. This means subjecting the application to extreme traffic spikes or resource constraints. The goal is to understand how it performs under pressure.
Stress testing also determines the system’s recovery capabilities after these extreme conditions. This reveals potential failure points and informs resilience planning.
Key Differences and Real-World Implications
While both tests assess performance, their methods and objectives are distinct. Load testing focuses on anticipated load, while stress testing explores extreme conditions. Load testing verifies performance during normal circumstances, while stress testing uncovers vulnerabilities under duress.
Neglecting either test can have significant consequences. Imagine an e-commerce platform that handles regular traffic flawlessly but crashes during a flash sale because of insufficient stress testing. Conversely, a system perpetually operating near capacity due to inadequate load testing optimization could consistently deliver a subpar user experience. These scenarios demonstrate the real-world impact of overlooking these vital testing approaches.
The growth of the performance testing market highlights the increasing demand for robust testing methodologies. After 2025, the industry is projected to experience substantial growth, with a predicted XX% CAGR through 2033. This expansion is driven by the need for effective load testing tools capable of managing complex modern applications. You can learn more about this growing market at Cognitive Market Research.
Integrating Stress and Load Testing into Your Strategy
Effectively incorporating both testing types necessitates a strategic approach. Begin by defining clear performance goals for your application. Then, design load tests that reflect realistic user behavior. Complement this with stress tests that simulate extreme, yet plausible, scenarios.
Regularly executing both tests, ideally integrated into the development lifecycle, ensures continuous performance optimization and robust resilience. This proactive approach strengthens the application’s ability to manage both expected and unexpected traffic fluctuations. Ultimately, the combined power of stress and load testing provides comprehensive insights into system performance, paving the way for a reliable and robust user experience.
Load Testing Methodologies That Actually Work
Beyond simply simulating a large number of users, effective load testing involves using diverse methodologies to uncover hidden performance bottlenecks. Successful organizations use various techniques, such as ramp-up tests, soak tests, and spike tests, to understand their systems’ behavior under different loads. This section explores these essential methodologies and how to apply them strategically.
Ramping Up Your Load Testing
Ramp-up tests gradually increase the system load over time. This approach simulates a steady increase in user traffic, letting you observe how the system responds to changing demands. You might be interested in: How to master load testing APIs. This type of testing reveals how performance degrades as load intensifies, pinpointing thresholds where response times suffer or errors emerge.
For example, a ramp-up test might start with 100 users and add 50 users every minute until reaching its predicted peak load. This controlled approach helps identify breaking points and optimal operating capacities.
The Importance of Soak Tests
Soak tests maintain a sustained, high load for an extended period, often hours or even days. This methodology reveals issues that might not appear during shorter tests, such as memory leaks, resource depletion, or performance degradation over time.
For instance, a soak test can uncover a slow memory leak not apparent in a shorter test but could eventually cause a system crash. This sustained pressure identifies long-term performance and stability issues.
Simulating Real-World Scenarios with Spike Tests
Spike tests simulate sudden traffic bursts, mimicking real-world events like flash sales or viral social media campaigns. This tests the system’s ability to handle dramatic fluctuations in user demand. This testing highlights the system’s elasticity and recovery capabilities.
A system that can quickly scale to meet the spike and then scale back down without impacting performance demonstrates robust resilience.
The following data chart visualizes the impact of different load testing methodologies on a hypothetical e-commerce website, comparing average response times under different scenarios.
As the chart shows, spike tests reveal the highest average response time because of the sudden traffic influx. Ramp-up tests show a gradual increase, while soak tests highlight a consistent, albeit slightly elevated, response time due to sustained high traffic. The baseline represents normal operating conditions.
To provide a more comprehensive overview of these methodologies, the following table compares their key aspects:
Load Testing Methodology Comparison
| Methodology | Primary Purpose | Ideal Use Cases | Limitations | Required Resources |
|---|---|---|---|---|
| Ramp-up Test | Identify system breaking points and optimal capacity | Determining how a system performs under increasing load, finding bottlenecks | Does not test system resilience to sudden load changes | Moderate |
| Soak Test | Uncover long-term performance issues like memory leaks | Evaluating system stability and resource usage over extended periods | Time-consuming; requires significant monitoring | High |
| Spike Test | Assess system resilience to sudden traffic changes | Simulating real-world events like flash sales or traffic spikes | May not reveal gradual performance degradation | Moderate |
This table summarizes the strengths and weaknesses of each load testing methodology, allowing teams to select the best approach for their specific needs.
Effectively using ramp-up, soak, and spike tests in your testing strategy helps identify potential performance bottlenecks before they impact users. This proactive approach lets you address vulnerabilities, ensuring your system remains reliable, stable, and capable of meeting fluctuating demands. Understanding how each methodology contributes to a holistic performance picture allows for informed decisions about system architecture, resource allocation, and capacity planning.
Stress Testing Techniques for Mission-Critical Systems

For systems like financial institutions, healthcare platforms, and high-traffic e-commerce sites, failure is simply not an option. Standard testing isn’t enough. These mission-critical systems require rigorous stress testing to uncover hidden vulnerabilities before they impact users. This involves pushing the system past its normal operating capacity to identify breaking points and assess its ability to recover. This section explores advanced stress testing approaches used by leading organizations to ensure system resilience.
Fault Injection Testing: Simulating Real-World Failures
Fault injection testing involves intentionally introducing faults, like simulated hardware failures, network outages, or software bugs, into the system to observe its behavior. By proactively creating these failure scenarios, teams can identify vulnerabilities and refine recovery procedures.
For instance, simulating a database connection failure can reveal how the system manages data loss or service interruptions. This proactive approach allows developers to find and fix weaknesses before they cause problems in the real world, building confidence in the system’s resilience. You might find this resource helpful: How to master stress testing.
Embracing Chaos Engineering
Chaos engineering goes a step further than fault injection by creating unpredictable disruptions in a controlled setting. This helps organizations see how their systems perform under chaotic conditions, mimicking the complexities of real-world scenarios where multiple failures can occur at once.
By observing the system’s response to these chaotic events, engineers can pinpoint architectural weaknesses and bolster the system’s overall resilience. This approach effectively simulates the unpredictable nature of production environments.
Component Isolation: Identifying Weak Links
Component isolation involves testing individual components of a system separate from the rest of the architecture. This practice helps pinpoint weaknesses in specific components that might be hidden during full-system tests. Isolating components allows you to see how each part of the system performs under stress independently.
For example, isolating a payment processing microservice allows for focused testing on its performance under extreme load, independent of other system elements. This targeted approach allows for better identification and remediation of vulnerabilities. Furthermore, understanding how individual components react to stress provides insights into the potential impact on the entire system.
Designing Realistic Worst-Case Scenarios
Effective stress testing hinges on designing realistic worst-case scenarios. This involves considering factors like peak traffic, spikes in data volume, and third-party service disruptions.
Financial institutions, for example, frequently conduct stress tests based on scenarios like major economic downturns. The 2025 DFAST stress tests implemented by U.S. regulators feature a “severely adverse” scenario with a smaller unemployment rate spike than in 2024 and a reduced decline in commercial real estate prices. You can learn more about the 2025 stress test scenarios. These realistic simulations offer crucial insights into system behavior under pressure.
Stress testing, when performed strategically with techniques like fault injection, chaos engineering, and component isolation, dramatically strengthens system resilience. Designing realistic worst-case scenarios allows for a comprehensive assessment and preparation for unexpected situations. This proactive approach facilitates continuous improvement and the creation of highly robust systems ready to withstand real-world challenges.
Selecting the Right Performance Testing Arsenal
Picking the right performance testing tools can feel overwhelming. This section simplifies the process, guiding you through various options, from free open-source tools to robust enterprise platforms. We’ll help you build a testing toolkit that aligns with your specific needs and budget. We’ll also cover essential features and offer practical tips for integrating performance testing into your existing workflow.
Open-Source vs. Enterprise: Finding the Right Balance
Deciding between open-source and enterprise performance testing tools depends on a few key factors. Open-source tools like JMeter (JMeter), Gatling (Gatling), and Locust (Locust) are budget-friendly and offer great flexibility. They are a good fit for smaller teams or projects with limited resources. However, they often require more technical knowledge and manual setup.
Enterprise tools such as LoadRunner (LoadRunner), NeoLoad (NeoLoad), and Silk Performer (Silk Performer) provide a complete set of features, advanced reporting, and dedicated support. These platforms offer robust performance and excellent scalability, but they do come with higher licensing fees. This makes them more suitable for larger companies with complex testing needs. Understanding these differences is essential for choosing the right tool for your team.
Essential Features: Separating the Must-Haves From the Nice-to-Haves
When you’re evaluating performance testing tools, some features are absolutely essential. Script creation simplicity affects how efficiently your team can create and maintain test scripts. The depth of reporting provided helps analyze results and pinpoint performance bottlenecks. Solid protocol support guarantees the tool can interact with your application’s communication methods. Finally, scaling capabilities are vital for mimicking real-world user loads.
Other features might seem appealing, but concentrate on these core elements to ensure the tool satisfies your fundamental testing needs. Prioritizing these key features will simplify your evaluation process and help you select the best tool for your overall performance testing strategy.
Integrating With Your CI/CD Pipeline
Integrating performance testing into your CI/CD pipeline is key to catching performance regressions early in the development cycle. Automating your performance tests within the CI/CD pipeline provides continuous monitoring and early identification of potential issues. This proactive approach ensures that updates and new code don’t negatively impact your application’s performance.
Using cloud-based platforms can further improve scalability and cost-effectiveness. This allows for the simulation of massive loads without a large investment in infrastructure. This adaptability enables thorough testing in various conditions, guaranteeing your application’s resilience.
Performance Testing Tool Evaluation Matrix
To simplify your selection process, we’ve compiled a comparison of popular stress and load testing tools:
To assist in your tool selection, the following table compares several popular performance testing options:
Performance Testing Tool Evaluation Matrix: Comprehensive comparison of popular stress and load testing tools across key selection criteria
| Tool | Cost Model | Learning Curve | Scalability | Protocol Support | CI/CD Integration | Best For |
|---|---|---|---|---|---|---|
| JMeter | Open-Source | Moderate | High | Extensive | Yes | Budget-conscious teams |
| Gatling | Open-Source | Moderate | High | Good | Yes | Developers |
| Locust | Open-Source | Easy | High | Limited | Yes | Python users |
| LoadRunner | Commercial | Steep | Very High | Extensive | Yes | Large enterprises |
| NeoLoad | Commercial | Moderate | High | Extensive | Yes | Enterprise performance |
| Silk Performer | Commercial | Steep | High | Extensive | Yes | Enterprise load testing |
This table summarizes key differences and similarities between several leading performance testing tools. By understanding the strengths and weaknesses of each tool and considering your specific needs, you can make a well-informed decision. Choosing the right tool for your performance testing arsenal empowers you to effectively identify performance bottlenecks and create high-performing, resilient applications. Also, consider incorporating realistic user behavior and implementing gradual load increases during testing for more accurate and practical results.
Meeting Regulatory Performance Requirements

For regulated industries, performance isn’t simply about a smooth user experience; it’s about meeting stringent compliance standards. Stress and load testing are essential for demonstrating adherence to these crucial regulatory requirements. This section explores how various sectors use these testing methods to fulfill their obligations, along with best practices for documentation and governance.
Financial Services and BASEL III Compliance
Financial institutions are under constant pressure to maintain system stability and prevent disruptions. BASEL III, a global regulatory framework, requires rigorous stress testing. This testing assesses a bank’s resilience under adverse economic conditions, simulating significant market fluctuations to evaluate potential losses and ensure sufficient capital reserves. This proactive approach helps protect the overall integrity of the financial system.
Healthcare and HIPAA Performance Obligations
In healthcare, performance directly impacts patient care. HIPAA regulations include performance obligations related to data availability and system reliability. Stress and load testing help healthcare organizations demonstrate their ability to maintain access to vital patient information, especially during peak demand or unexpected outages. This robust testing is essential for ensuring data integrity and secure patient access.
Payment Processors and PCI DSS Requirements
The PCI DSS establishes stringent security standards for handling sensitive payment card information. Payment processors must demonstrate that their systems can withstand potential attacks and maintain data integrity. Stress and load testing verify system resilience under simulated attack conditions or high transaction volumes. This helps ensure the security of financial transactions and mitigates risk.
Documenting Your Testing: A Key to Compliance
Maintaining comprehensive documentation is critical for demonstrating compliance. Thoroughly documenting your testing methodology, results, and remediation plans is essential not only for internal review but also for providing evidence during audits. Clear documentation streamlines the audit process and supports compliance efforts.
Regulatory stress tests are constantly evolving. For example, the 2025 regulatory stress tests emphasize real estate vulnerabilities, with the NCUA’s scenario mirroring the Federal Reserve’s framework. More information about the 2025 stress test scenario summary is available online.
Establishing a Governance Framework
A strong governance framework ensures that your stress and load testing program aligns with both regulatory requirements and business goals. This framework should clearly define responsibilities, establish testing frequencies, and outline procedures for reviewing and updating testing protocols. A well-defined governance structure strengthens compliance and improves the effectiveness of your testing strategy.
Maintaining Appropriate Evidence
Maintaining appropriate evidence is key for demonstrating compliance during audits. This evidence should include test plans, execution results, and documentation of all remediation efforts. Properly organizing and storing this information allows organizations to respond efficiently to regulatory inquiries.
Implementing Risk-Based Testing Frequencies
Implementing risk-based testing frequencies helps ensure resources are allocated effectively. Systems with higher risk or those processing sensitive data require more frequent and rigorous testing. This focused approach optimizes resource use and strengthens security in the most vulnerable areas.
By integrating these strategies, organizations can not only meet their regulatory obligations but also enhance system resilience and user experience. This proactive approach cultivates a culture of compliance while delivering a reliable and secure user experience. Ultimately, stress and load testing provides a framework for meeting regulatory performance requirements and protecting your organization’s reputation.
Learning From Epic Performance Failures
Performance failures can be costly, impacting both brand reputation and revenue. Analyzing past incidents offers valuable lessons about the importance of robust stress testing and load testing. This section examines notable system failures where insufficient testing played a key role, uncovering common patterns that contribute to these catastrophic performance issues.
Case Study: Black Friday Retail Platform Crash
Many retailers have faced the nightmare scenario of a website crash during peak traffic, especially on Black Friday. One prominent example involves a major retailer whose site became unavailable for several hours due to an unexpected traffic surge. The consequences were significant, resulting in substantial lost sales and damaged customer trust. The root cause was traced to inadequate load testing that failed to accurately simulate real-world user behavior. The retailer focused on concurrent users but overlooked the rapid browsing and checkout activity typical of Black Friday shoppers.
This case study highlights the crucial need for realistic load testing scenarios that mirror actual user interactions. Following the incident, the retailer implemented more comprehensive load tests, incorporating diverse user profiles and traffic patterns.
Case Study: Financial System Failure During Market Volatility
Financial systems are especially vulnerable to performance problems during periods of market volatility. One notable incident involved a major stock exchange experiencing significant trade processing delays due to a sudden spike in trading activity. These delays led to substantial financial losses for traders and diminished trust in the exchange. The investigation revealed that the exchange’s stress testing hadn’t adequately considered extreme market fluctuations or the cascading effect of multiple systems failing concurrently.
This incident underscores the necessity of robust stress testing that anticipates worst-case scenarios, including potential failures of dependent systems. The stock exchange responded by implementing more rigorous stress testing protocols that accounted for broader market conditions and their impact on system performance.
Case Study: Streaming Service Outage During Major Event
Streaming services have become a central part of our entertainment landscape. One popular service suffered a major outage during a highly anticipated sporting event, preventing millions of viewers from accessing the live stream. The problem stemmed from underestimating the concurrent user load and insufficiently testing the system’s ability to scale rapidly. This highlights the importance of understanding and accurately simulating traffic patterns during load tests, particularly for events expected to draw a massive audience.
Recognizing Warning Signs in Your Systems
These case studies reveal several recurring patterns that contribute to performance failures:
-
Insufficient Test Duration: Short tests may not uncover issues like memory leaks or gradual performance degradation. Soak tests, which maintain high loads for extended periods, are essential for identifying these long-term performance problems.
-
Unrealistic User Scenarios: Load tests must accurately reflect real-world user behavior, including simulating the variety of user actions, timing, and network conditions. Consider using real user data to create precise traffic models.
-
Failure to Test Third-Party Dependencies: Many modern applications rely on external services or APIs. Performance testing must incorporate these dependencies to identify potential bottlenecks or points of failure.
Transforming Testing Practices: A Path to Resilience
Organizations that have experienced performance failures often overhaul their testing practices. These changes include:
-
Implementing Comprehensive Performance Testing Strategies: This involves combining load tests, stress tests, and other performance testing methods like spike testing to simulate various real-world scenarios.
-
Integrating Performance Testing into CI/CD Pipelines: Continuous performance testing helps detect performance regressions early in the development cycle, preventing issues from reaching production. Jenkins is a popular tool for CI/CD.
-
Adopting a Culture of Continuous Improvement: Regularly analyzing performance test results and incorporating feedback helps identify areas for improvement and refine testing strategies over time.
By learning from past failures and implementing robust testing strategies, organizations can build resilient systems capable of handling unexpected demands and maintaining a positive user experience.
Ready to elevate your performance testing? GoReplay is an open-source tool designed to capture and replay live HTTP traffic into your testing environments, enabling you to use real production traffic for more effective and realistic testing. Check out GoReplay at https://goreplay.org and ensure your applications are always performing at their best.