Elevate Your QA Game: Mastering Regression Testing
Effective regression testing strategies are critical for delivering high-quality software. This article presents eight key regression testing strategies to improve your QA process. Learn how to choose the right approach for your needs, from the comprehensive “retest all” method to advanced AI-driven techniques. We’ll explore the strengths and weaknesses of each strategy, including regression test selection, risk-based testing, test case prioritization, automated and coverage-based regression testing, model-based approaches, and the emerging field of AI-driven regression testing. Discover how the right regression testing strategy, combined with tools like GoReplay, can boost your team’s efficiency and product quality.
1. Retest All Approach
The Retest All approach is the most comprehensive of all regression testing strategies. It involves re-executing every single test case within the existing test suite after any modification to the codebase. This exhaustive method ensures maximum test coverage, leaving no stone unturned in the pursuit of identifying potential regressions. While it provides the highest level of confidence in system quality, it’s important to understand that this thoroughness comes at a cost: significant time and resource investment. This strategy is most suitable for mission-critical systems where even minor bugs can have catastrophic consequences, such as in aerospace or medical software, and when significant changes are implemented in the application’s architecture or core functionality.

This approach deserves its place on the list of regression testing strategies because it represents the maximum achievable coverage and serves as a benchmark against which other, more efficient strategies can be measured. Its simplicity and thoroughness make it easily understandable and implementable, even for teams with less experience in regression testing. The key features of this approach include a complete re-execution of all test cases without any selection or prioritization, thus offering maximum coverage of the system’s functionality without requiring in-depth test case analysis.
The benefits of the Retest All approach are clear: comprehensive coverage, simple implementation, high confidence in system quality, and elimination of the risk of missing defects due to skipped tests. However, it’s crucial to acknowledge the significant drawbacks. This strategy is extremely time and resource intensive, making it often impractical for large applications with extensive test suites. It’s not cost-effective for minor code changes and can significantly delay release cycles.
Pros:
- Provides comprehensive coverage: Guarantees that all existing functionality is tested, minimizing the risk of undetected regressions.
- Simple to implement and understand: Straightforward methodology requiring no complex analysis or prioritization.
- Highest confidence in system quality: Delivers the greatest assurance that the software remains stable and functional after changes.
- No risk of missing defects due to skipped tests: Every test case is executed, eliminating the chance of overlooking regressions in less frequently tested areas.
Cons:
- Extremely time and resource-intensive: Requires substantial investment in testing time and resources, potentially impacting project timelines and budgets.
- Often impractical for large applications: The sheer number of test cases in large systems can render this approach unfeasible.
- Not cost-effective for minor changes: Executing all tests for small modifications can be an unnecessary overhead.
- Can delay release cycles significantly: The extensive testing time can push back release dates and impede rapid development cycles.
Examples of Successful Implementation:
- NASA’s space flight software testing: Where absolute reliability is paramount, the Retest All approach ensures comprehensive validation of critical systems.
- Medical device testing in compliance with FDA regulations: Stringent regulatory requirements necessitate rigorous testing to ensure patient safety.
- Financial trading platforms before major releases: Given the high stakes and potential for significant financial impact, comprehensive regression testing is essential.
Tips for Implementation:
- Automate as many test cases as possible: Automation significantly reduces execution time and allows for efficient re-testing.
- Use parallel execution environments: Running tests concurrently across multiple machines or virtual instances speeds up the testing process.
- Consider cloud-based testing infrastructure: Cloud platforms offer scalability and flexibility for managing large test suites and parallel execution.
- Reserve this approach for mission-critical releases or major architectural changes: Limit its use to situations where the highest level of quality assurance is absolutely necessary.
When choosing a regression testing strategy, the Retest All approach offers the ultimate safety net but comes with significant costs. Carefully weigh the need for absolute certainty against the practical constraints of time and resources. For many projects, a more targeted approach, such as risk-based or regression test selection, might offer a better balance between thoroughness and efficiency.
2. Regression Test Selection (RTS)
Regression Test Selection (RTS) is a crucial regression testing strategy that optimizes the testing process by focusing on efficiency without compromising effectiveness. Instead of re-running every single test case after a code change (the “retest-all” approach), RTS intelligently selects and executes only those tests affected by the modifications. This targeted approach drastically reduces testing time and resources, making it particularly valuable in agile and continuous integration/continuous deployment (CI/CD) environments where rapid releases are the norm. RTS earns its place as a top regression testing strategy due to its ability to balance thoroughness with speed, making it ideal for fast-paced software development lifecycles.
How RTS Works:
RTS relies on analyzing the dependencies between the codebase and the existing test suite. This involves understanding which parts of the code are impacted by a specific change and then mapping those changes to the tests that exercise those specific areas. Various techniques enable this analysis:
- Code Change Analysis: Tools examine the differences between code versions (e.g., using Git diffs) to pinpoint the modified sections.
- Traceability Matrices: These matrices document the relationships between requirements, code components, and test cases, facilitating the identification of relevant tests.
- Dependency Graphs: Visual representations of dependencies between code modules help determine the ripple effect of changes and identify all potentially affected tests.
- Selection Algorithms: RTS employs algorithms, broadly categorized as static (analyzing code without execution) or dynamic (analyzing code during execution), to automate the selection process. Static analysis often uses control flow graphs and data flow analysis, while dynamic analysis may involve instrumentation and runtime tracing.
Features and Benefits:
- Selective Test Execution: Only the necessary tests are run, saving significant time and computational resources.
- Change Impact Analysis: RTS pinpoints the affected areas, allowing testers to focus their efforts where they matter most.
- Code-to-Test Traceability: Clear links between code and tests ensure that all relevant tests are identified and executed.
- Variety of Selection Algorithms: Different algorithms cater to various project needs and code complexities.
Pros:
- Significantly reduced testing time compared to the retest-all strategy.
- More cost-effective for frequent releases and iterative development.
- Focused testing on areas directly impacted by changes, leading to faster identification of regressions.
- Balances coverage and efficiency, offering a practical compromise between exhaustiveness and speed.
Cons:
- Requires sophisticated analysis tools to perform dependency analysis and test selection.
- Potential to miss defects if the chosen selection algorithm is flawed or the traceability information is incomplete.
- Overhead of maintaining traceability between code and tests, demanding meticulous documentation and updates.
- May not catch regression defects arising from unexpected interactions between seemingly unrelated components, particularly if the analysis focuses solely on direct dependencies.
Examples of Successful Implementation:
- Google: Employs RTS for testing its Chrome browser, given the vast codebase and frequent updates.
- Microsoft: Integrates RTS into its Visual Studio Test Platform, providing developers with tools for targeted testing.
- Facebook: Utilizes RTS within its testing infrastructure to support continuous deployment of its massive social media platform.
Actionable Tips for Implementation:
- Implement code coverage analysis: Gain insights into which parts of the code are exercised by which tests.
- Use static analysis tools: Identify dependencies between components and predict the impact of changes.
- Maintain detailed change logs: Facilitate accurate test selection by documenting code modifications thoroughly.
- Periodically validate the effectiveness of your selection algorithm: Ensure its accuracy and adjust as needed.
- Combine with risk-based approaches: Prioritize testing of critical components and functionalities, even if they aren’t directly affected by the current changes.
Key Figures in RTS:
- Gregg Rothermel: A pioneer in regression test selection research, contributing significantly to the field.
- Elbaum, Malishevsky, and Rothermel: Researchers who have developed several influential RTS algorithms.
By strategically implementing RTS, software development teams can optimize their regression testing efforts, accelerate release cycles, and improve overall product quality. While the initial setup and maintenance might require investment, the long-term benefits in terms of efficiency and cost savings make RTS a compelling strategy for modern software development.
3. Risk-Based Regression Testing
Risk-based regression testing is a powerful strategy within the broader suite of regression testing strategies. It focuses on optimizing testing efforts by prioritizing test cases based on the inherent risk associated with different functional areas or components of the software. Instead of blindly retesting everything, this approach directs resources towards the areas most likely to contain defects or where failures would have the greatest impact on business operations. This intelligent allocation maximizes the effectiveness of testing, particularly when faced with time constraints, budget limitations, or rapidly approaching deadlines.

This approach hinges on a thorough risk assessment of the application’s components. This involves identifying potential failure points and evaluating the likelihood of those failures occurring and their potential impact on the business. Factors considered include the complexity of the code, the frequency of usage of a particular feature, the business criticality of the functionality, and the potential financial or reputational damage a failure could cause. Test cases are then prioritized based on this assessment, with high-risk areas receiving more rigorous and frequent testing. This often involves a weighted test case selection process, where tests covering critical functionalities are given higher weightage. The depth of test coverage becomes variable, directly correlating to the risk level of each component. A high-risk module might see 100% test coverage, while a low-risk, stable component might receive significantly less.
Risk-based regression testing deserves its place in the list of regression testing strategies because it offers a practical and efficient way to manage testing efforts, especially in dynamic environments. It ensures that critical functionalities are thoroughly tested, maximizing the chances of identifying and addressing critical defects before they impact users.
Features:
- Risk assessment of application components
- Prioritization based on business impact and technical complexity
- Weighted test case selection
- Variable test coverage based on risk levels
Pros:
- Optimizes testing effort based on business priorities
- Effective resource allocation to critical areas
- Higher defect detection in critical functionality
- Practical for projects with tight timelines
- Adaptable to changing business requirements
Cons:
- Requires expertise in risk assessment
- May miss defects in lower-risk areas
- Subjective if risk assessment criteria aren’t well-defined
- Needs regular updates as the system evolves
Examples of Successful Implementation:
- Banking Systems: Focusing regression testing on payment processing modules, ensuring secure and reliable transactions.
- E-commerce Platforms: Prioritizing checkout and payment gateway testing to maximize conversion rates and prevent revenue loss.
- Healthcare Systems: Emphasizing patient data handling components to maintain data integrity and comply with regulations.
Tips for Implementation:
- Develop a risk matrix considering factors like complexity, usage frequency, and business impact.
- Involve business stakeholders in the risk assessment process to gain a comprehensive understanding of business priorities.
- Use historical defect data to inform risk calculations and identify recurring problem areas.
- Re-evaluate risk levels after major architectural changes or the introduction of new features.
- Combine risk-based testing with other regression testing approaches over time to ensure broader coverage of less critical areas.
Popularized By:
- ISTQB (International Software Testing Qualifications Board)
- James Bach - context-driven testing advocate
- Cem Kaner - software testing methodology researcher
When to use this approach: Risk-based regression testing is particularly beneficial in situations where time and resources are limited, when dealing with complex systems with numerous interconnected components, and when software updates or changes are frequent. It provides a structured way to prioritize testing efforts and maximize the return on investment in testing activities by focusing on what matters most to the business.
4. Test Case Prioritization
Test Case Prioritization is a crucial regression testing strategy that optimizes the order of test execution within a test suite. Unlike test selection, which chooses a subset of tests, prioritization ensures that all tests are run, but in a sequence designed to uncover critical defects faster. This approach is invaluable for maximizing the impact of testing, especially when time is limited. By prioritizing tests based on factors like historical failure rates, code changes, requirement coverage, or execution time, teams can frontload the execution of the most important tests. This allows for early detection of critical issues, giving developers valuable feedback sooner and improving the overall efficiency of the development process.
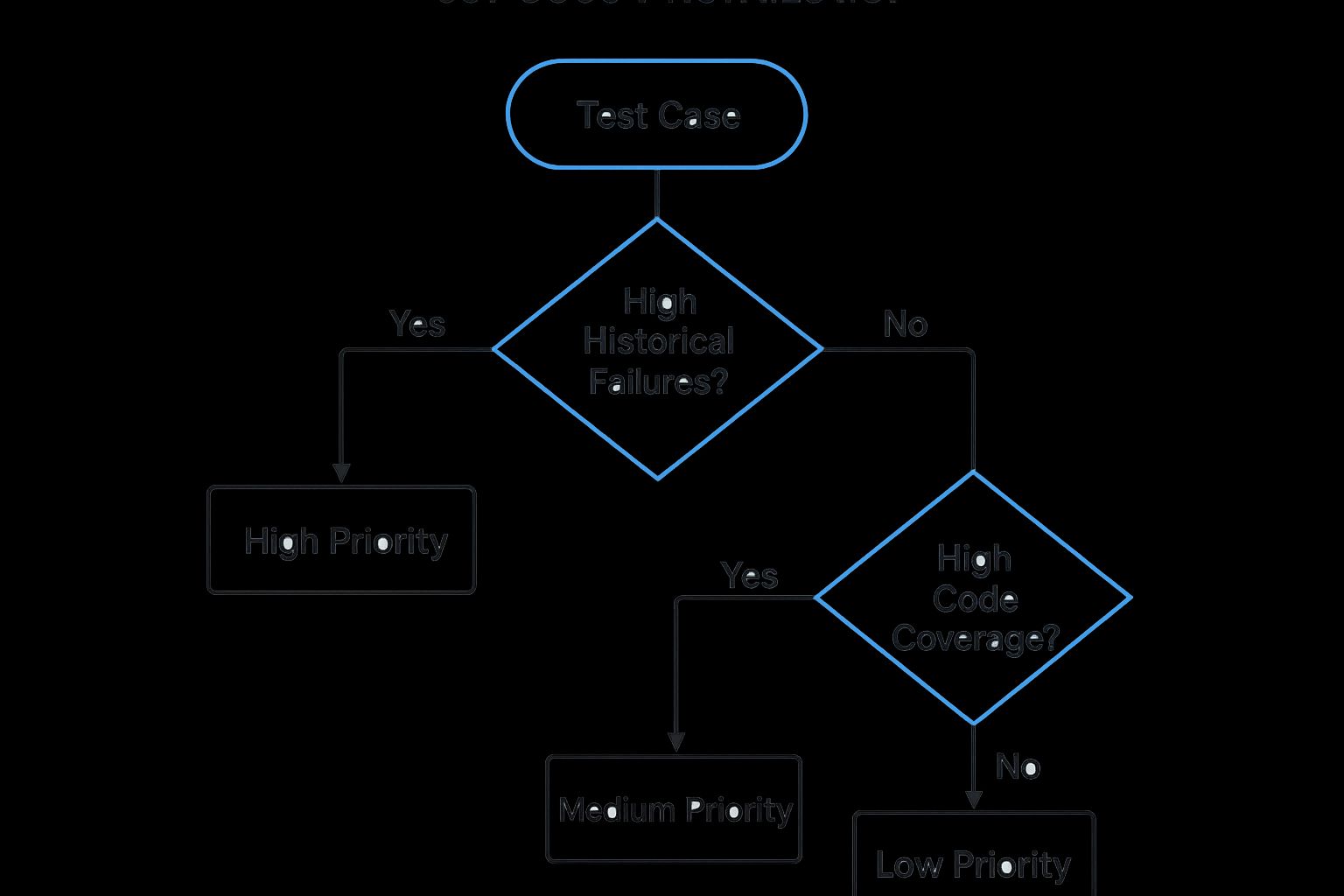
The infographic above illustrates a decision tree for choosing the right test case prioritization technique. It highlights the key factors to consider when prioritizing test cases, such as the availability of historical data, the criticality of the application being tested, and the project’s time constraints.
Several successful implementations highlight the value of Test Case Prioritization. Mozilla uses prioritization for nightly builds of Firefox, enabling them to quickly identify regressions introduced by new code. Similarly, Amazon integrates test prioritization into its continuous integration pipeline, ensuring rapid feedback on code changes. Spotify prioritizes their mobile application test suites to focus on core functionalities and user experience during limited testing windows. These real-world examples demonstrate how Test Case Prioritization contributes to faster feedback loops and more efficient regression testing.
Features of Test Case Prioritization:
- Ordered Execution: Test cases are run in a calculated order, not randomly.
- Multiple Criteria: Prioritization can be based on factors like code coverage, historical failure rates, and business criticality.
- Full Test Suite Execution: All tests are eventually executed, ensuring comprehensive coverage.
- Continuous Reprioritization: The order can be adjusted based on new information or feedback.
Pros:
- Early Defect Detection: Critical bugs are found sooner, reducing their impact.
- Improved Test Effectiveness: Maximizes results when time is constrained.
- Faster Feedback: Developers receive crucial information earlier in the cycle.
- Complete Coverage: Maintains thorough testing despite prioritization.
- Adaptable: Suitable for various project needs and contexts.
Cons:
- Complexity: Effective prioritization algorithms can be complex to implement.
- Data Dependency: Some methods rely on historical data, which might not be available.
- Prioritization Overhead: Calculating the order adds overhead to each cycle.
- Unchanged Overall Time: Doesn’t reduce the total testing time, just shifts the order of defect discovery.
When and why to use Test Case Prioritization:
Test case prioritization becomes particularly valuable in situations where:
- Time Constraints: When facing tight deadlines, prioritize tests that offer the highest probability of uncovering critical defects quickly.
- Continuous Integration/Continuous Delivery (CI/CD): Rapid feedback is essential in CI/CD pipelines, making test prioritization crucial for efficient testing within short cycles.
- Limited Resources: Prioritization helps make the most of limited testing resources by focusing on high-impact tests.
- Frequent Releases: With frequent releases, prioritizing tests helps ensure that the most critical functionalities are thoroughly tested before each release.
Tips for Effective Test Case Prioritization:
- Combine Criteria: Use multiple factors for prioritization, not just one. For example, combine code coverage with historical failure data.
- Collect Historical Data: Implement systems to track test failures and execution time to inform future prioritization efforts.
- Consider Time Constraints: Choose prioritization algorithms that align with your project’s time constraints. Simpler algorithms might be more suitable for shorter cycles.
- Automate: Automate the prioritization process to minimize manual overhead and ensure consistency.
- Evaluate Regularly: Periodically review and refine your prioritization strategy to maximize its effectiveness and adapt to evolving project needs.
The decision process highlighted in the infographic allows teams to choose the optimal method for prioritizing tests. By considering factors such as historical data availability and project timelines, teams can implement a prioritization strategy that best suits their specific needs. This structured approach enables a more effective and targeted regression testing process, leading to faster identification of critical issues and improved software quality. This approach aligns with the philosophies promoted by figures like Sebastian Elbaum and Gregg Rothermel, prominent researchers in software testing and test optimization, and discussed in forums like the Google Test Automation Conference (GTAC).
5. Automated Regression Testing
Automated regression testing is a crucial strategy within the broader suite of regression testing approaches. It leverages specialized tools and frameworks to execute pre-defined test cases automatically, comparing actual results against expected outcomes without requiring manual intervention. This method systematically verifies that recent code changes haven’t adversely impacted existing functionalities. This approach is particularly valuable in fast-paced development environments, especially those employing Continuous Integration/Continuous Deployment (CI/CD) pipelines. By automating the regression testing process, teams can ensure frequent and consistent testing, catching potential issues early and preventing them from reaching production. Automated regression testing encompasses various levels, from granular unit tests verifying individual components to comprehensive end-to-end tests assessing the entire application flow.

This strategy necessitates an upfront investment in building the required automation infrastructure, including selecting appropriate tools, writing test scripts, and setting up the execution environment. Features such as script-based test execution, automated result verification, seamless integration with CI/CD pipelines, cross-browser and cross-platform compatibility, and comprehensive reporting dashboards are hallmarks of effective automated regression testing. This investment, however, yields significant long-term benefits, especially as the application grows in complexity.
Automated regression testing deserves its place on this list because it’s the most scalable and efficient way to handle the ever-increasing demand for thorough regression testing in modern software development. The benefits are numerous, including significant time savings compared to manual testing, consistent and reliable results due to the elimination of human error, enabling faster feedback cycles through frequent testing, and seamless scalability as the application evolves. Companies like Google, with their Test Automation Platform (TAP) running millions of tests daily, exemplify the power and efficiency of this approach. Similarly, Facebook leverages Jest for end-to-end testing, Netflix utilizes automated testing for continuous deployment, and Airbnb employs Enzyme and Jest for component testing. These examples highlight the widespread adoption and success of automated regression testing in leading tech companies.
However, automated regression testing isn’t without its challenges. The initial investment in automation development can be high, and there’s ongoing maintenance overhead as the application evolves. Effective implementation requires technical expertise, and not all tests are suitable for automation due to cost-effectiveness considerations. Additionally, automated tests can suffer from brittleness, leading to false positives or negatives.
To effectively implement automated regression testing, prioritize automating stable, high-value, and frequently executed tests. Ensure proper test isolation and state management, design for maintainability by incorporating abstraction layers, and leverage data-driven testing to maximize coverage. Implement robust error handling and reporting mechanisms, and strive for a balanced approach that encompasses unit, integration, and UI automation for optimal coverage. Learn more about Automated Regression Testing. Frameworks like Selenium and Appium for web and mobile testing respectively, JUnit/TestNG for unit testing, and the modern web testing framework Cypress are popular tools that facilitate this automation. The principles of continuous integration, championed by figures like Martin Fowler, underscore the importance of automated regression testing in maintaining software quality and accelerating delivery cycles.
6. Coverage-Based Regression Testing
Coverage-Based Regression Testing is a powerful strategy within the broader spectrum of regression testing strategies. It offers a data-driven approach to test selection, ensuring that modifications to your codebase are thoroughly vetted while minimizing unnecessary testing. This method leverages code instrumentation to track which parts of your application are exercised during test execution. By analyzing code coverage metrics, you can strategically select test cases that optimally cover changed areas, focusing your testing efforts where they matter most.
How it Works:
This technique involves instrumenting your code to monitor which lines, branches, or paths are executed during testing. Tools collect this execution data and generate reports visualizing the coverage achieved. By comparing coverage reports between different versions of your code, you can pinpoint areas affected by recent changes and ensure they are adequately tested. This “delta coverage” analysis helps prioritize testing on the modified parts of your application, avoiding redundant execution of tests irrelevant to the latest updates.
Features:
- Code instrumentation for coverage measurement: Tools inject instrumentation code to track execution.
- Multiple coverage criteria (statement, branch, path, function): Measure coverage at different granularities, from individual lines of code to entire functions.
- Delta coverage analysis between versions: Identify changes in coverage between builds.
- Coverage visualization and reporting: Generate reports and visualizations to understand coverage levels.
- Integration with version control systems: Link coverage data with code changes for better analysis.
Pros:
- Objective, data-driven test selection: Removes guesswork from test selection.
- Ensures modified code is adequately tested: Focuses testing efforts where they are needed most.
- Identifies gaps in test coverage: Pinpoints areas needing additional tests.
- Reduces redundant test execution: Avoids running tests unrelated to recent changes.
- Provides measurable testing effectiveness metrics: Track and report coverage progress.
Cons:
- Overhead of code instrumentation: Can impact application performance during testing.
- May focus on code rather than functionality: High coverage doesn’t necessarily mean all functionality is tested.
- Doesn’t account for test effectiveness in finding defects: Coverage doesn’t guarantee bug-free code.
- High coverage doesn’t guarantee high quality: Code can be fully covered by tests and still be poorly designed.
- Requires specialized tools and infrastructure: Implementing and maintaining coverage analysis tools can be complex.
Examples of Successful Implementation:
- JaCoCo in Java projects: JaCoCo is a popular open-source library for code coverage analysis in Java development.
- Google’s use of coverage metrics in Chrome development: Google leverages coverage data extensively to ensure the quality and stability of the Chrome browser.
- Microsoft’s code coverage analysis in Azure DevOps pipelines: Coverage analysis is integrated into Azure DevOps pipelines to automate coverage measurement and reporting.
Actionable Tips:
- Combine multiple coverage criteria: Use a combination of statement, branch, and path coverage for a more comprehensive view.
- Set coverage targets based on component criticality: Focus on higher coverage for critical components.
- Use differential coverage to focus on changed code: Prioritize testing based on changes in coverage.
- Analyze uncovered code paths for potential test additions: Identify areas where tests are lacking.
- Don’t treat coverage as the only quality metric: Use coverage in conjunction with other quality measures.
- Integrate coverage measurement into CI/CD pipelines: Automate coverage tracking and reporting.
When and Why to Use This Approach:
Coverage-Based Regression Testing is particularly valuable when dealing with large and complex codebases where understanding the impact of changes can be challenging. It is especially useful in Agile and DevOps environments where frequent code changes require efficient and targeted regression testing. This strategy helps ensure that new code is adequately tested and that existing functionality remains intact after modifications, contributing to higher software quality and faster release cycles.
Popularized By:
- SonarQube: A widely used platform for code quality and coverage analysis.
- Codecov: A dedicated code coverage reporting tool with integrations for various CI/CD platforms.
- Istanbul: A popular JavaScript code coverage tool.
- Brian Marick: An early advocate for the use of test coverage analysis in software testing.
This approach deserves its place among regression testing strategies due to its objective, data-driven nature. By providing clear metrics and insights into test coverage, it empowers teams to make informed decisions about testing priorities and resource allocation, ultimately leading to more efficient and effective regression testing.
7. Model-Based Regression Testing
Model-Based Regression Testing represents a sophisticated approach to regression testing strategies, leveraging formal models of the system under test to drive the testing process. Instead of relying solely on manually created test cases, this method utilizes models such as state machines, activity diagrams, or sequence diagrams to abstract the application’s behavior. By analyzing the impact of changes on these models, Model-Based Testing allows for the automatic generation and selection of highly targeted regression test cases. This systematic and automated approach makes it a powerful technique within a comprehensive regression testing strategy.
How it Works:
The core of Model-Based Testing lies in creating a formal representation of the system’s intended behavior. This model serves as a blueprint against which the actual implementation can be verified. When changes are introduced to the application, the corresponding model is updated to reflect these modifications. Specialized tools then analyze the delta between the original and updated model, automatically generating test cases designed to exercise the affected areas. These tests ensure that the modified behaviors function as expected and integrate correctly with the rest of the system.
Features and Benefits:
- Formal System Modeling: Utilizing standardized modeling languages like UML, state machines, and sequence diagrams provides a clear and unambiguous representation of system behavior.
- Automated Test Case Generation: Generating test cases directly from the model dramatically reduces the manual effort required for test design and significantly speeds up the testing process.
- Change Impact Analysis: Model-Based Testing excels at pinpointing the specific areas affected by code changes, enabling focused and efficient regression testing.
- Traceability: Clear traceability between model elements and code facilitates easier debugging and impact analysis.
- Behavior-Driven Test Selection: Tests are selected based on the modeled behavior, ensuring that critical functionalities and integration points are thoroughly tested.
Pros:
- Systematic Approach: Offers a structured and repeatable process for regression test generation.
- Early Testing: Models can be created early in the development lifecycle, enabling earlier testing and faster identification of defects.
- Better Test Coverage: Facilitates better coverage of complex integration points and scenarios.
- Reduced Manual Effort: Automates test case design, freeing up testers for more exploratory and higher-level testing activities.
- Alignment with System Specifications: Closely ties testing to the system specifications embedded in the model.
Cons:
- Expertise Required: Requires skilled personnel proficient in formal modeling techniques.
- Model Maintenance Overhead: Creating and maintaining accurate models can be time-consuming and resource-intensive.
- Model Accuracy is Crucial: The effectiveness of the testing relies heavily on the accuracy and completeness of the model.
- Tooling Dependency: Requires specialized tools and frameworks for model creation, analysis, and test generation.
- Learning Curve: Teams unfamiliar with modeling concepts will face a learning curve.
Examples of Successful Implementation:
- Automotive: Simulink models are commonly used for Model-Based Testing of complex automotive systems.
- Aerospace: State machine models are frequently employed for testing critical control systems in aerospace applications.
- Telecom: Sequence diagrams are often utilized for testing communication protocols in the telecom industry.
- IBM: IBM has successfully leveraged Model-Based Testing for their middleware products.
Actionable Tips:
- Start Small: Begin by modeling critical components or modules rather than attempting to model the entire system at once.
- Familiar Notations: Use modeling notations that are familiar to your team to reduce the learning curve.
- Synchronization is Key: Ensure that the models are kept synchronized with the implementation throughout the development lifecycle.
- Combine with Other Techniques: Model-Based Testing can be effectively combined with other regression testing techniques for comprehensive coverage.
- Domain-Specific Languages: Leverage domain-specific modeling languages when appropriate to enhance model expressiveness and efficiency.
- Bidirectional Traceability: Implement bidirectional traceability between models and code to improve debugging and impact analysis.
Why Model-Based Testing Deserves its Place:
Model-Based Regression Testing earns its place among essential regression testing strategies due to its ability to systematically and automatically generate targeted test cases. It shifts the focus from manual test creation to model design and analysis, resulting in improved test coverage, reduced testing time, and better alignment with system specifications. While the initial investment in model creation and tooling can be significant, the long-term benefits in terms of improved software quality and reduced testing costs make it a valuable addition to any robust regression testing strategy. For organizations dealing with complex systems and frequent changes, Model-Based Testing offers a powerful and efficient way to ensure the reliability and stability of their software.
8. AI-Driven Regression Testing
As software systems grow in complexity, regression testing becomes increasingly challenging. Traditional methods can become time-consuming and resource-intensive, struggling to keep pace with rapid release cycles. This is where AI-driven regression testing emerges as a powerful strategy within the broader spectrum of regression testing strategies. It leverages machine learning and artificial intelligence techniques to optimize and streamline the entire regression testing process. This includes intelligent test selection, prioritization, execution, and analysis.
Instead of blindly re-running all existing tests, AI algorithms analyze historical test data, code changes, and system usage patterns to make data-driven decisions about which tests are most relevant and likely to uncover regressions. These models continuously learn from past test outcomes, improving their accuracy and effectiveness over time. AI can even predict areas of the codebase with a high probability of defects, enabling targeted testing and faster identification of critical issues.
Features of AI-Driven Regression Testing:
- Machine learning algorithms for test selection and prioritization: Focus testing efforts on the most critical areas.
- Predictive analytics for defect-prone areas: Proactively identify potential problem spots.
- Self-healing test scripts: Automatically adapt to UI changes, reducing test maintenance.
- Natural language processing for requirements-to-test mapping: Streamline test case creation from requirements.
- Anomaly detection in test results: Highlight unexpected behaviors and potential issues.
- Intelligent test data generation: Create relevant and diverse test data automatically.
Pros:
- Adaptive and continuously improving test strategy: The system learns and adapts to changing codebases and requirements.
- Reduces testing effort while maintaining effectiveness: Optimize test suites and reduce redundant tests.
- Identifies non-obvious relationships between code changes and tests: Uncover hidden dependencies and potential regressions.
- Better handling of flaky tests: Identify and mitigate the impact of unreliable tests.
- Faster analysis of test results and root causes: Quickly pinpoint the source of failures.
- Can optimize for multiple objectives simultaneously: Balance test coverage, execution time, and risk.
Cons:
- Requires significant historical data for effective learning: Initial results may be limited until sufficient data is accumulated.
- Black-box nature may reduce transparency in decision-making: Understanding why specific tests were chosen can be challenging.
- Initial setup cost and complexity: Implementing AI-driven tools can be complex and require specialized expertise.
- May require specialized skills in data science: Managing and interpreting AI models may require data science skills.
- Still an emerging field with evolving best practices: Standards and best practices are still being developed.
Examples of Successful Implementation:
- Microsoft’s CNTK-based test prediction system
- Facebook’s Sapienz automated testing platform
- Testim’s AI-based test automation
- Applitools’ visual AI testing
- mabl’s machine learning test automation
Tips for Implementing AI-Driven Regression Testing:
- Start with a specific testing problem rather than implementing AI broadly.
- Collect and structure test execution history to enable learning.
- Combine AI recommendations with human judgment.
- Use explainable AI techniques to understand test selection decisions.
- Gradually increase AI autonomy as confidence in the system grows.
- Benchmark AI-driven approaches against traditional methods.
When and Why to Use AI-Driven Regression Testing:
This approach is particularly valuable for large and complex software projects with frequent releases, where traditional regression testing becomes unwieldy. It’s also beneficial when dealing with rapidly changing UI, as self-healing test scripts can significantly reduce maintenance overhead. If your team is struggling with lengthy test cycles and increasing testing costs, AI-driven regression testing can offer a significant advantage by optimizing test execution and identifying critical issues faster.
For a deeper dive into the strategic implications of AI for businesses, learn more about AI-Driven Regression Testing. This resource can offer valuable insights for enterprise transformation through AI.
This item deserves its place in the list of regression testing strategies due to its potential to revolutionize the way we approach software quality. By leveraging the power of AI, organizations can achieve significant improvements in testing efficiency, effectiveness, and overall software quality. Pioneers like Jason Arbon, author of ‘AI for Software Testing’, and companies like Applitools, Sauce Labs, Google, and TestProject are driving innovation in this field, making AI-driven regression testing an increasingly viable and valuable strategy for modern software development.
Regression Testing Strategies Comparison
| Strategy | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Retest All Approach | High (simple concept, extensive effort) | Very High (time and resources) | Maximum coverage, highest confidence in quality | Mission-critical systems, major architectural changes | Comprehensive coverage, simple to understand, no risks missed |
| Regression Test Selection (RTS) | Moderate to High (requires analysis tools) | Moderate (tools and maintenance) | Reduced testing time with focused coverage | Continuous integration, frequent releases | Balances coverage and efficiency, cost-effective |
| Risk-Based Regression Testing | Moderate (needs risk expertise) | Moderate | Optimized testing effort focused on critical areas | Projects with tight timelines, business-critical modules | Prioritizes tests by risk, adapts to changing priorities |
| Test Case Prioritization | High (complex algorithms, data needed) | Moderate to High | Early fault detection, complete coverage | Time-constrained testing cycles, large test suites | Faster defect discovery, better feedback to developers |
| Automated Regression Testing | High (automation infrastructure needed) | High (initial investment, technical) | Consistent, frequent testing with fast feedback | CI/CD pipelines, large and growing systems | Saves time on repeated tests, scales well, reliable |
| Coverage-Based Regression Testing | Moderate to High (instrumentation and tools) | Moderate | Objective test selection, coverage gap identification | Projects needing measurable test effectiveness | Data-driven, reduces redundant tests, coverage metrics |
| Model-Based Regression Testing | High (formal modeling expertise) | High (model creation and tools) | Systematic test generation, early lifecycle testing | Complex systems, safety-critical domains | Aligns with specifications, better integration coverage |
| AI-Driven Regression Testing | Very High (AI setup, data and skills) | High (data, skills, tooling) | Adaptive testing, improved efficiency and defect prediction | Large-scale, data-rich environments, evolving systems | Continuous improvement, predictive, handles flaky tests |
Choosing the Right Regression Testing Strategy
Selecting the optimal regression testing strategy is crucial for maintaining software quality and accelerating development cycles. As we’ve explored, the range of regression testing strategies, from the comprehensive retest-all approach to more focused methods like risk-based and regression test selection, offers tailored solutions for different project needs. Key takeaways include understanding the importance of test case prioritization, the power of automation for continuous integration and delivery, and the benefits of advanced techniques like coverage-based and model-based testing. Mastering these concepts empowers teams to optimize their testing efforts, minimize risk, and deliver high-quality software efficiently. By carefully considering factors like project size, budget constraints, and risk tolerance, and selecting the most suitable regression testing strategy, organizations can significantly improve the software development lifecycle and deliver superior products. Remember, the right approach to regression testing isn’t one-size-fits-all; it’s about finding the perfect fit for your specific context.
Enhance your chosen regression testing strategy by incorporating real-world user behavior. GoReplay captures and replays live HTTP traffic, creating a realistic test environment that helps you identify and address potential issues before they impact your users. Explore the power of GoReplay for robust and efficient regression testing: GoReplay