Protecting Sensitive Data: Why Data Anonymization Matters
Data breaches and stringent privacy regulations make protecting sensitive information paramount. This listicle presents eight powerful data anonymization tools to help your organization safeguard data while enabling critical activities like testing and analytics. Learn about key features and capabilities of leading data anonymization tools including ARX, Privacera, and IBM InfoSphere Optim, so you can choose the right solution to de-identify sensitive data and maintain compliance.
1. ARX Data Anonymization Tool
ARX is a powerful open-source data anonymization tool designed to help organizations protect sensitive personal information while preserving data utility. It offers a comprehensive suite of privacy-enhancing technologies, making it a valuable asset for researchers, developers, and businesses working with sensitive data. ARX excels in providing a user-friendly graphical interface, enabling even non-technical users to perform complex anonymization tasks with ease. This, combined with its robust set of features and active community support, makes it a top contender among data anonymization tools. Its focus on compliance with data protection regulations like GDPR and HIPAA further solidifies its position as a go-to solution for privacy-conscious organizations.
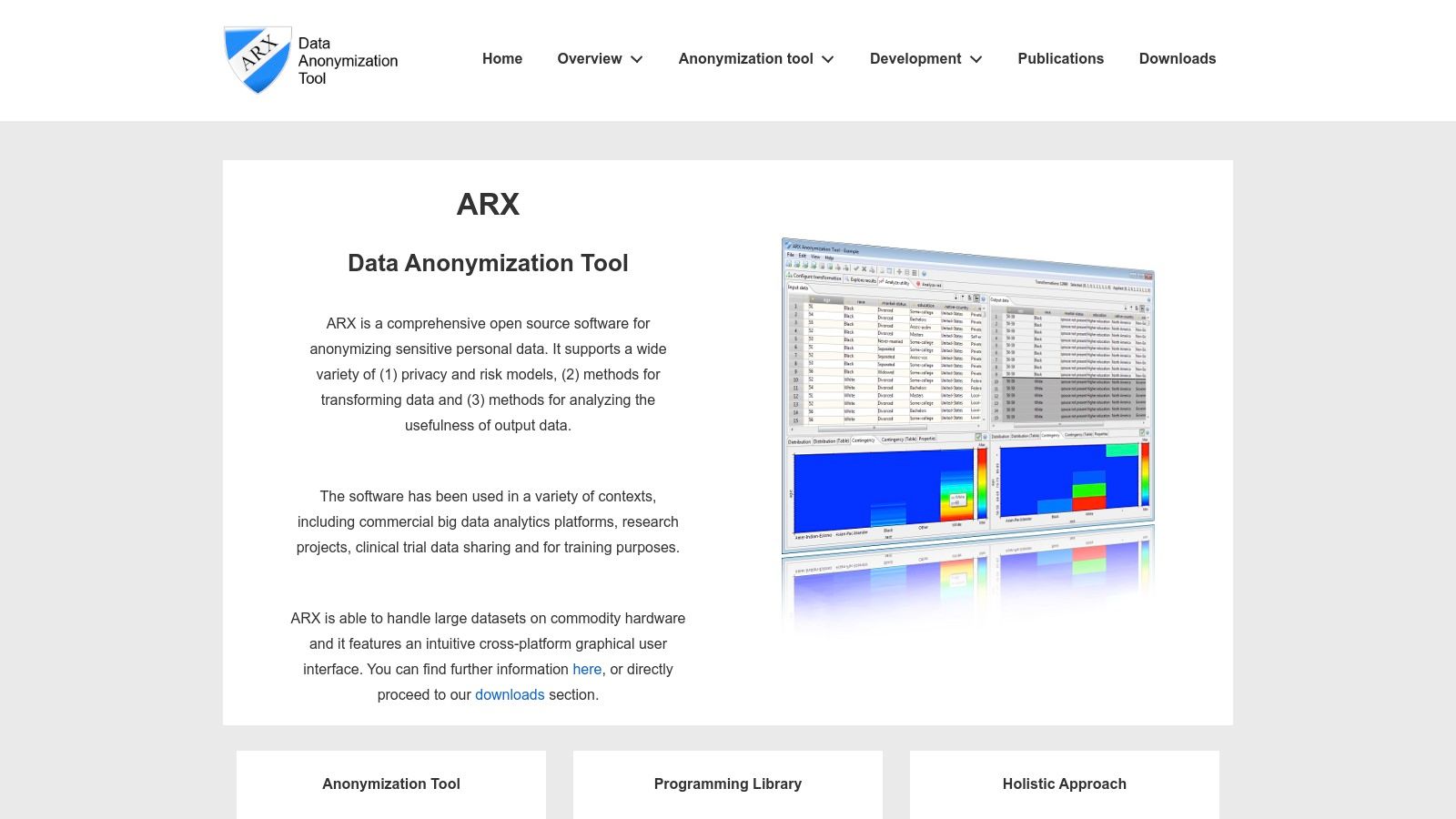
ARX’s strength lies in its implementation of various privacy models, including k-anonymity, l-diversity, t-closeness, and differential privacy algorithms. These models offer different approaches to anonymization, allowing users to choose the best fit for their specific needs and risk tolerance. For instance, k-anonymity ensures that each individual’s record is indistinguishable from at least k-1 other records within the dataset, protecting against identity disclosure. L-diversity further enhances k-anonymity by ensuring diversity within sensitive attributes, preventing attribute disclosure. T-closeness builds upon these by minimizing the difference in the distribution of sensitive attributes between the anonymized dataset and the original dataset. Finally, differential privacy adds noise to the data, making it difficult to infer individual information while preserving statistical properties of the dataset.
Beyond the core anonymization functionalities, ARX provides robust risk analysis capabilities. Its re-identification risk assessment helps users understand the potential for individuals to be re-identified from the anonymized data, allowing for informed decisions about the appropriate level of anonymization. The tool also offers data utility analysis, measuring the usefulness of the anonymized data for its intended purpose. Maintaining a balance between privacy and utility is crucial, and ARX’s built-in metrics help users achieve this balance. The support for hierarchical data transformations allows for flexible and granular anonymization, catering to complex data structures.
For developers and IT teams, ARX’s open-source nature is a significant advantage. It allows for customization and integration with existing systems. The active community provides valuable support and resources, ensuring that users can find solutions to any challenges they encounter. ARX requires a Java runtime environment, which is readily available across most platforms.
While ARX boasts a user-friendly GUI, its command-line interface provides advanced users with greater control and scripting capabilities. This makes it a versatile tool suitable for both interactive use and automated data anonymization workflows within larger data pipelines.
One potential drawback of ARX is its scalability limitations with very large datasets. The memory-intensive nature of complex transformations can pose challenges for resource-constrained environments. While improvements are continuously being made, users dealing with extremely large datasets might need to explore alternative solutions or consider distributed processing approaches.
Implementation and Setup Tips:
- Download the latest version: Visit the ARX website (https://arx.deidentifier.org/) and download the appropriate version for your operating system.
- Install Java: Ensure you have a compatible Java Runtime Environment (JRE) installed on your system.
- Follow the tutorials: ARX provides extensive documentation and tutorials that guide users through the anonymization process, from data import to risk analysis and anonymization strategy selection.
- Experiment with different privacy models: Explore the various privacy models offered by ARX and adjust parameters to find the optimal balance between privacy and data utility.
- Monitor resource usage: Keep an eye on memory consumption during complex transformations, especially with large datasets.
ARX is a valuable tool for anyone dealing with sensitive personal data. Its comprehensive features, open-source nature, and user-friendly interface make it a powerful solution for achieving data anonymization and complying with data privacy regulations. While scalability can be a concern for extremely large datasets, ARX remains a strong choice for most anonymization needs, providing a balance of power, flexibility, and ease of use.
2. Privacera
Privacera is a robust enterprise-grade data security and governance platform designed to address the complex challenges of data privacy and compliance. It offers a comprehensive suite of tools for data anonymization, masking, and privacy protection, making it a valuable asset for organizations working with sensitive data across various environments, including cloud and on-premises infrastructure. This platform distinguishes itself through its centralized policy management, enabling organizations to define and enforce consistent data privacy rules across their entire data landscape. For those seeking comprehensive data anonymization tools, Privacera deserves serious consideration, especially for organizations dealing with large-scale data operations and stringent regulatory requirements.
Privacera excels in its ability to handle both dynamic data masking and static data anonymization. Dynamic masking allows real-time obfuscation of sensitive data for authorized users, ensuring that data remains protected while still accessible for legitimate business operations. Static data anonymization, on the other hand, creates a separate, anonymized copy of the data, ideal for development, testing, and analytics purposes without compromising the original sensitive information. This dual capability allows organizations to tailor their data protection strategies to specific use cases, maximizing both security and utility.
A core strength of Privacera lies in its centralized privacy policy management. Through a unified interface, organizations can define granular access controls, masking rules, and anonymization policies, ensuring consistent enforcement across all supported data platforms. This centralized approach simplifies data governance and streamlines compliance efforts, particularly important for organizations operating in heavily regulated industries like finance and healthcare. The platform supports a broad range of data platforms including Hadoop, Snowflake, AWS, Azure, and GCP, enabling organizations to implement a cohesive data security strategy across their hybrid and multi-cloud environments. This interoperability minimizes the need for platform-specific solutions, reducing complexity and management overhead.
Privacera also offers robust data discovery and classification capabilities. It can automatically scan and classify sensitive data across various data sources, providing organizations with a clear understanding of their data landscape and potential vulnerabilities. This real-time visibility empowers organizations to proactively identify and protect sensitive data, mitigating risks associated with data breaches and regulatory non-compliance. By integrating with major data platforms and databases, Privacera ensures seamless data protection without disrupting existing workflows. This integration simplifies the implementation process and allows organizations to leverage their existing data infrastructure.
For software developers, Privacera offers a secure way to access production-like data for testing and development without exposing sensitive information. Quality Assurance engineers can leverage anonymized data sets for rigorous testing without compromising data privacy. Enterprise IT teams benefit from the centralized policy management and robust security features, streamlining data governance and compliance efforts. DevOps professionals can integrate Privacera into their CI/CD pipelines to automate data anonymization and masking processes. Finally, tech-savvy business leaders can leverage Privacera’s comprehensive reporting and auditing features to gain insights into their data security posture and demonstrate compliance with relevant regulations.
While Privacera offers a powerful suite of tools, it’s important to consider its potential drawbacks. The enterprise-grade features come with enterprise-level pricing, which may be prohibitive for smaller organizations with limited budgets. Furthermore, the initial setup and configuration process can be complex, often requiring dedicated resources and specialized expertise. Ongoing management and maintenance also require dedicated personnel, adding to the overall cost of ownership. Organizations considering Privacera should carefully evaluate their needs and resources to ensure a successful implementation.
Despite these considerations, Privacera’s comprehensive capabilities, enterprise-scale performance, and strong integration ecosystem make it a leading choice for organizations seeking advanced data anonymization and privacy protection. The investment in Privacera is justified for organizations with stringent security requirements, complex data environments, and a commitment to robust data governance. For further information and detailed pricing, you can visit their website at https://privacera.com/. Comparing Privacera with other data anonymization tools like Immuta and Data.gov reveals similar strengths in policy management and platform support, but Privacera stands out with its focus on enterprise-grade performance and its broader range of data governance capabilities. Implementing Privacera effectively requires careful planning, dedicated resources, and collaboration between IT and security teams. Engage with Privacera’s professional support and services to streamline the implementation process and maximize the platform’s potential.
3. IBM InfoSphere Optim
IBM InfoSphere Optim is a comprehensive enterprise data management solution offering robust data anonymization tools alongside features for test data management, data archiving, and privacy protection. Designed to cater to large-scale enterprise environments grappling with complex data landscapes, InfoSphere Optim provides a suite of powerful tools to streamline data operations while safeguarding sensitive information. Its strength lies in its ability to handle large volumes of data from diverse sources, making it a suitable choice for organizations with complex data management needs. This solution ensures regulatory compliance and reduces the risk of data breaches by allowing organizations to create realistic yet anonymized test data, crucial for application development and testing.

One of the key strengths of InfoSphere Optim is its advanced data masking capabilities. It employs a variety of data anonymization tools and techniques, including substitution, shuffling, perturbation, and encryption, to protect sensitive data while maintaining the statistical integrity of the dataset. This is essential for developing and testing applications in a safe and compliant manner, without risking the exposure of real customer data. For instance, developers can use InfoSphere Optim to create a masked copy of production data for testing new features, ensuring that sensitive information like credit card numbers or social security numbers are replaced with realistic but anonymized values. Similarly, quality assurance teams can leverage masked data to perform rigorous testing without compromising data privacy.
InfoSphere Optim goes beyond basic data masking by offering comprehensive test data management functionalities. It allows for the creation of realistic and referentially intact test data subsets, empowering development and testing teams to work with data that accurately mirrors the production environment without jeopardizing sensitive information. This capability drastically reduces the time and effort required for test data provisioning, streamlining the development lifecycle. Further enhancing its data management prowess, InfoSphere Optim provides data archiving and lifecycle management capabilities, enabling organizations to effectively manage the storage and retention of their data.
The platform excels in maintaining referential integrity during the masking process. This ensures that relationships between data across different tables are preserved, maintaining data consistency and usefulness for testing and development. For example, if a customer record is masked in one table, the corresponding order records in related tables will also be masked accordingly, preserving the relationship between the customer and their orders. This feature is crucial for maintaining data accuracy and preventing issues during testing and development that can arise from broken relationships. Furthermore, its seamless integration with the broader IBM data management ecosystem makes it a natural choice for organizations already invested in IBM technology.
While InfoSphere Optim offers a powerful set of features, it’s essential to consider its limitations. As an enterprise-grade solution, it comes with high licensing and implementation costs, making it less accessible to smaller organizations or projects with limited budgets. The complexity of its configuration and maintenance demands specialized skills and may necessitate dedicated administrator training. The learning curve can be steep, requiring substantial investment in training and expertise. Lastly, its strong focus on the IBM technology stack may present integration challenges for organizations operating with heterogeneous environments. Alternative data anonymization tools like Delphix and DataVeil offer comparable features with potentially lower costs and simpler implementations, making them viable alternatives, especially for organizations outside the IBM ecosystem.
Implementation Tips:
- Phased Approach: Implement InfoSphere Optim in phases, focusing on specific use cases initially, like test data management for a particular application.
- Training: Invest in thorough training for administrators to ensure they can effectively configure and manage the platform.
- Collaboration: Foster collaboration between development, testing, and data management teams to leverage InfoSphere Optim effectively.
Technical Requirements & Pricing:
Specific technical requirements and pricing for IBM InfoSphere Optim are not publicly available and are typically obtained through direct engagement with IBM sales representatives. This bespoke approach allows IBM to tailor the solution and pricing to the specific needs and scale of the organization.
More information about IBM InfoSphere Optim can be found on their website.
4. Informatica Persistent Data Masking
Informatica Persistent Data Masking (IPDM) is a powerful data anonymization tool designed for enterprises seeking robust and comprehensive data protection. It allows organizations to create realistic, yet anonymized copies of their sensitive data for development, testing, training, and analytics purposes, without compromising compliance with data privacy regulations like GDPR, CCPA, and HIPAA. IPDM stands out for its breadth of features, strong enterprise integration capabilities, and focus on compliance. This makes it a valuable addition to the arsenal of any organization dealing with sensitive data. IPDM allows for both static and dynamic masking, meaning it can permanently alter data at rest or provide masked data on the fly, depending on the user or application requesting it. This flexibility caters to a wide range of data protection scenarios.
One of the core strengths of Informatica Persistent Data Masking lies in its extensive library of pre-built masking functions. These functions cover common data types like names, addresses, credit card numbers, social security numbers, and more. This allows users to quickly apply appropriate masking techniques without needing to develop custom scripts. Furthermore, IPDM supports custom algorithm development for organizations with unique masking requirements. Format-preserving encryption (FPE) is another key feature, enabling data to be masked while retaining its original format. This is crucial for maintaining data usability in testing and development environments. For example, a masked credit card number will still look like a credit card number, enabling applications to function correctly without access to real sensitive data. The cross-platform support ensures that IPDM can protect data residing across various database systems, simplifying data masking efforts for organizations with heterogeneous IT infrastructures. Crucially, IPDM provides comprehensive audit trails and compliance reporting features, enabling organizations to track masking activities and demonstrate adherence to data privacy regulations.
IPDM shines in enterprise environments due to its strong integration capabilities with other Informatica products and third-party systems. This enables seamless incorporation into existing data management workflows. For instance, IPDM can be integrated with Informatica PowerCenter for data masking during ETL processes or with Informatica Data Quality for data cleansing and standardization before masking. This tight integration simplifies data masking operations and enhances overall data governance.
While IPDM offers a robust set of features and benefits, it’s essential to be aware of its potential drawbacks. The licensing model can be expensive, particularly for smaller organizations. Implementation can be resource-intensive, requiring specialized expertise and careful planning. Proper training is essential to fully leverage IPDM’s capabilities, adding to the overall cost and implementation time.
Practical Applications and Use Cases:
- Application Development and Testing: Providing developers and testers with masked data sets that mimic real data without compromising sensitive information.
- Data Warehousing and Analytics: Creating anonymized data extracts for reporting, business intelligence, and data analysis.
- Training and Education: Equipping training teams with realistic yet safe data sets for educational purposes.
- Outsourcing and Third-Party Sharing: Securely sharing data with external partners and vendors without exposing sensitive customer information.
- Compliance with Data Privacy Regulations: Meeting the data anonymization and pseudonymization requirements of regulations like GDPR, CCPA, and HIPAA.
Implementation and Setup Tips:
- Clearly Define Masking Requirements: Identify sensitive data elements and determine the appropriate masking techniques for each.
- Develop a Comprehensive Masking Strategy: Outline the scope of masking, data sources, masking rules, and implementation timeline.
- Leverage Pre-built Masking Functions: Utilize IPDM’s extensive library of pre-built functions to accelerate implementation.
- Thoroughly Test Masking Procedures: Validate the effectiveness of masking rules and ensure data integrity.
- Monitor and Audit Masking Activities: Regularly review audit trails to track masking operations and ensure compliance.
Pricing and Technical Requirements:
Informatica uses a customized pricing model for IPDM based on specific needs and data volumes. Contacting Informatica directly for a quote is recommended. Technical requirements vary depending on the specific deployment environment and integrations. Detailed information can be found on the Informatica website.
Comparison with Similar Tools:
Compared to other data anonymization tools like Delphix and Data Masker, Informatica offers a more comprehensive set of features, particularly regarding enterprise integration and compliance reporting. While tools like Data Masker might be more cost-effective for smaller organizations, IPDM’s robust features make it a strong choice for enterprise-level data protection.
Website: https://www.informatica.com/products/data-security/persistent-data-masking.html
5. Delphix Dynamic Data Platform
Delphix Dynamic Data Platform stands out among data anonymization tools by offering a unique approach to data security and provisioning. Instead of directly masking production data, Delphix creates virtual data copies, significantly reducing storage costs and enabling faster processing. These virtual copies can then be masked and provisioned for various non-production environments, ensuring data privacy while facilitating development, testing, and analytics. This approach addresses the increasing demand for secure data access across the software development lifecycle, making Delphix a valuable tool for organizations prioritizing both speed and security. It’s a particularly strong choice for businesses dealing with large datasets and complex data environments where traditional masking methods might prove cumbersome and slow.
Delphix’s core strength lies in its virtual data copies with integrated masking capabilities. This allows for rapid provisioning of secure data for various teams without impacting the performance or security of the production environment. Imagine needing to set up a test environment with realistic but anonymized customer data. With Delphix, instead of copying and masking the entire production database, which can take hours or even days, a virtual copy can be created and masked within minutes. This dramatically accelerates development and testing cycles, enabling faster time-to-market for new features and applications.
Delphix provides self-service data provisioning, empowering developers and testers to access anonymized data on demand without requiring intervention from the IT department. Automated masking policy enforcement ensures consistent application of data privacy policies across all virtual copies, simplifying compliance efforts. Furthermore, real-time data refresh capabilities keep non-production environments up-to-date with minimal downtime, providing development teams with access to the most current data representations. This level of automation and self-service streamlines workflows and reduces bottlenecks in the development process.
The platform also features API-driven automation and integration, allowing seamless integration with existing DevOps toolchains and CI/CD pipelines. This fosters a more agile and efficient development environment. For instance, Delphix can be integrated with tools like Jenkins or GitLab to automate the creation and provisioning of masked data for testing as part of the continuous integration process.
While Delphix offers significant advantages, it’s important to consider its potential drawbacks. The initial investment and licensing costs can be high, making it a more viable option for larger enterprises. Its complex architecture requires specialized expertise to implement and manage effectively, which may necessitate dedicated training or the hiring of skilled personnel. Finally, while Delphix supports a wide range of databases and applications, it may have limited support for some legacy systems. Organizations with older infrastructure should carefully evaluate compatibility before committing to Delphix.
Compared to traditional data masking tools that operate directly on production data, Delphix’s virtual data approach offers superior performance and flexibility. While tools like Data Masker and IRI FieldShield are effective for static data masking, they lack the dynamic provisioning and rapid refresh capabilities of Delphix. This makes Delphix a more compelling solution for organizations requiring frequent access to updated, anonymized data.
For implementation, organizations should first assess their data landscape and identify the specific use cases for anonymized data. This will help determine the appropriate licensing and infrastructure requirements. Working with a Delphix certified partner can significantly streamline the implementation process and ensure proper configuration. Ongoing maintenance and management require specialized expertise, so it’s essential to have dedicated resources or a service agreement in place.
Delphix doesn’t publicly list pricing information, encouraging potential customers to contact their sales team for a customized quote based on their specific needs and usage requirements. This approach allows them to tailor solutions to the individual client, but it also makes it difficult to compare costs upfront without direct engagement.
In conclusion, Delphix Dynamic Data Platform earns its place among the top data anonymization tools due to its innovative virtual data approach, robust automation capabilities, and strong focus on performance optimization. While it represents a significant investment, the benefits of faster development cycles, improved data security, and reduced storage costs can be substantial for organizations with demanding data provisioning needs. For software developers, QA engineers, and DevOps professionals dealing with large datasets and complex data environments, Delphix offers a powerful and efficient solution for secure data access and management. You can explore their offerings further on their website: https://www.delphix.com/
6. Microsoft SQL Server Data Masking
Microsoft SQL Server Data Masking offers a straightforward, integrated solution for protecting sensitive data within your SQL Server databases. This built-in feature provides real-time, dynamic data obfuscation, allowing developers, testers, and other authorized personnel to work with realistic data sets without exposing actual sensitive information. This capability is particularly valuable for non-production environments like development, testing, training, and reporting, where access to real data is necessary but the risk of exposure needs to be mitigated. It makes SQL Server Data Masking a convenient tool for organizations already utilizing the SQL Server ecosystem, streamlining data anonymization efforts and reducing the need for complex third-party solutions. This tool is particularly beneficial for adhering to data privacy regulations like GDPR, CCPA, and HIPAA, helping organizations maintain compliance while enabling data utilization for various purposes.
One of the key advantages of SQL Server Data Masking is its seamless integration with the existing SQL Server security model. Masking rules are applied at the column level and managed through SQL Server Management Studio (SSMS), a familiar interface for SQL Server administrators. This integration simplifies the setup and configuration process significantly. Administrators can define masking policies based on user roles and permissions, ensuring that sensitive data is only revealed to authorized individuals. For instance, a developer might see masked credit card numbers while a customer service representative can access the full, unmasked information. This granular control over data access enhances security and streamlines compliance efforts.
SQL Server Data Masking uses a set of built-in masking functions to obfuscate data. These functions include:
- Full masking: Replaces the entire value with a specific character, like ‘X’ or ’#’.
- Partial masking: Reveals only a portion of the data, such as the last four digits of a credit card number.
- Random data generation: Substitutes sensitive values with randomly generated data of the same data type, maintaining data integrity for testing purposes.
- Date shifting: Alters date values by a specific offset while preserving the date format.
- Email masking: Protects email addresses by replacing characters with ‘X’ while retaining the domain name.
While these functions offer a good starting point for basic data masking, they are less comprehensive than what specialized data anonymization tools provide. This limitation can be a constraint for organizations with complex masking requirements or needing advanced techniques like format-preserving encryption or tokenization.
The primary advantage of SQL Server Data Masking lies in its inclusion with existing SQL Server licensing. This means no additional costs for organizations already using SQL Server. It is straightforward to implement and requires no separate infrastructure. This simplicity makes it a readily accessible option for quickly masking sensitive data in SQL Server databases. However, its limitation to SQL Server environments and dynamic-only masking capabilities restricts its broader applicability across diverse database systems and static data masking needs. Other tools offer more extensive masking techniques and cross-platform support, making them more suitable for organizations with complex requirements or heterogeneous database landscapes. Despite these limitations, SQL Server Data Masking remains a valuable data anonymization tool for organizations heavily reliant on the SQL Server ecosystem, offering a quick, simple, and cost-effective way to protect sensitive information within their SQL Server databases.
For implementing data masking in SQL Server, consider these tips:
- Identify sensitive data: Clearly define which columns require masking based on regulatory requirements and internal policies.
- Choose appropriate masking functions: Select the function that best suits the data type and desired level of obfuscation.
- Test thoroughly: Verify that the masking rules are working as expected and do not impact application functionality.
- Monitor and audit: Regularly review masking policies and audit data access to ensure ongoing compliance.
For further information and detailed documentation, refer to the official Microsoft documentation: https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
7. MOSTLY AI
MOSTLY AI distinguishes itself in the realm of data anonymization tools by offering a synthetic data platform. Instead of directly modifying sensitive data, MOSTLY AI leverages advanced machine learning techniques to generate entirely new, artificial datasets that statistically mirror the original data while guaranteeing privacy. This approach unlocks opportunities for data sharing, analytics, and machine learning model development without exposing sensitive information. This unique approach places it firmly among the top contenders for robust data anonymization solutions. Organizations dealing with particularly sensitive data, or those seeking to maximize data utility while minimizing privacy risks, will find MOSTLY AI to be a valuable asset.
For software developers, QA engineers, and DevOps professionals, MOSTLY AI provides a powerful tool for creating realistic test environments. Synthetic data generated by the platform can be used to populate staging environments, perform rigorous testing without compromising real user data, and train machine learning models on diverse and representative datasets. This eliminates the need for complex data masking procedures or the risk of exposing production data during testing phases.
Enterprise IT teams and tech-savvy business leaders can leverage MOSTLY AI for data analysis and business intelligence initiatives. The platform enables organizations to share data with external partners, conduct market research, and develop data-driven insights without compromising the privacy of individuals. This facilitates collaboration and innovation while adhering to strict data privacy regulations like GDPR and CCPA.
MOSTLY AI supports various data types, including tabular, time-series, and mixed data, broadening its application across diverse domains. For example, in the financial sector, it can be used to generate synthetic transaction data for fraud detection model training. In healthcare, it can create synthetic patient records for research and development purposes, preserving patient confidentiality. Similarly, retail companies can use MOSTLY AI to generate synthetic customer data for personalized marketing campaigns without revealing individual customer details.
The platform is cloud-based and provides API access, facilitating seamless integration with existing data pipelines and workflows. This scalability allows organizations to process large volumes of data efficiently and adapt to evolving data needs. The cloud-based architecture also minimizes the need for on-premise infrastructure, reducing setup and maintenance overhead.
While MOSTLY AI offers a powerful solution for data anonymization, understanding its strengths and limitations is crucial for effective implementation. One of its key advantages is the generation of high-quality synthetic data with strong privacy guarantees. The platform uses differential privacy techniques, ensuring that individual data points cannot be reconstructed from the synthetic dataset. However, this advanced functionality comes with a subscription-based pricing model, which might be a factor for budget-conscious organizations. Pricing details are available on request from Mostly AI directly.
Another aspect to consider is the requirement of understanding synthetic data concepts. While the platform is designed for ease of use, familiarity with the principles of synthetic data generation can enhance the effectiveness of its implementation. Users need to define the statistical properties and relationships they want to preserve in the synthetic dataset. MOSTLY AI offers considerable flexibility in this regard, but achieving optimal results requires careful consideration of the specific data and use case.
While MOSTLY AI excels in many scenarios, it’s essential to acknowledge that it may not be the ideal solution for every data anonymization need. For instance, use cases requiring strict data fidelity or specific data transformations might be better addressed by other data anonymization techniques like data masking or pseudonymization. Furthermore, while the platform provides controls over data generation, users have limited direct influence over the specific transformations applied to individual data points. This level of control might be necessary for some use cases requiring precise data manipulation for anonymization.
In summary, MOSTLY AI provides a powerful and innovative approach to data anonymization through synthetic data generation. Its cloud-based platform, support for various data types, and strong privacy guarantees make it a compelling choice for numerous applications. However, organizations should carefully evaluate their specific requirements, budget, and technical expertise to determine if MOSTLY AI is the right fit for their data anonymization needs. For those seeking to maximize data utility while adhering to strict privacy standards, MOSTLY AI offers a powerful and forward-thinking solution. You can explore their platform and offerings further at https://mostly.ai/.
8. Oracle Data Masking and Subsetting
Oracle Data Masking and Subsetting is a robust enterprise solution designed for comprehensive data anonymization and test data management within Oracle environments. It allows organizations to create realistic, yet anonymized, copies of their production data for development, testing, training, and reporting purposes without compromising sensitive information. This makes it a valuable tool for organizations adhering to data privacy regulations like GDPR, CCPA, and HIPAA. Its tight integration with the Oracle ecosystem provides a streamlined experience for users already working within that environment. This tool deserves its place on this list due to its powerful features, focus on data integrity, and enterprise-grade capabilities.
One of the core strengths of Oracle Data Masking and Subsetting lies in its extensive library of pre-defined masking formats. These formats cover a wide range of data types, including names, addresses, credit card numbers, social security numbers, and dates. This allows users to quickly apply appropriate masking techniques without needing to develop custom solutions. Furthermore, for unique data masking requirements, the tool supports the development of custom masking functions using PL/SQL, providing flexibility and control over the anonymization process.
Beyond simple masking, Oracle Data Masking and Subsetting excels in maintaining referential integrity. When masking related data across multiple tables, the tool ensures that relationships remain consistent. For instance, if a customer ID is masked in one table, it will be masked consistently across all related tables. This is crucial for creating realistic test datasets that accurately reflect the relationships within the production data. This feature significantly reduces the risk of introducing inconsistencies that could lead to inaccurate testing results or flawed development efforts.
The integrated data subsetting capabilities further enhance the utility of this tool. Organizations can create smaller, representative subsets of their production data, reducing storage costs and processing time for non-production environments. This is particularly beneficial for testing and development, where a full copy of the production data might be unnecessary and resource-intensive.
For organizations operating within the Oracle ecosystem, the deep integration with Oracle Database and Enterprise Manager offers a significant advantage. This integration simplifies deployment, management, and monitoring of the masking and subsetting processes. Security is another strong point, with the tool leveraging Oracle’s robust security infrastructure to protect sensitive data during the anonymization process.
While Oracle Data Masking and Subsetting offers powerful capabilities, it’s essential to be aware of the potential drawbacks. Licensing costs can be substantial, especially for enterprise-level features. The tool is primarily optimized for Oracle environments, and deploying it in multi-vendor database environments can be complex. Effective configuration and utilization also require a degree of Oracle expertise.
Practical Applications & Use Cases:
- Application Development: Create realistic test data for new application development and bug fixing without exposing real customer data.
- QA Testing: Generate masked datasets for performance and functional testing, ensuring the quality and reliability of applications.
- Training: Provide developers and other personnel with realistic, anonymized data for training purposes.
- Reporting and Analytics: Create masked datasets for reporting and business intelligence without compromising sensitive information.
- Compliance with Data Privacy Regulations: Anonymize sensitive data before sharing it with third parties or using it for non-production purposes.
Implementation Tips:
- Analyze data sensitivity: Before implementing, thoroughly analyze your data to identify sensitive information requiring masking.
- Plan masking formats: Carefully select the appropriate masking formats for each data type to ensure realistic yet anonymized data.
- Test thoroughly: After implementing masking rules, rigorously test the masked data to ensure accuracy and consistency.
- Monitor performance: Regularly monitor the performance of masking jobs to identify and address any potential bottlenecks.
Comparison with Similar Tools: While tools like Delphix and Informatica Data Masking offer similar functionalities, Oracle Data Masking and Subsetting benefits from deep integration within the Oracle ecosystem. This tight integration can be a decisive factor for organizations already heavily invested in Oracle technologies.
Pricing and Technical Requirements: Pricing for Oracle Data Masking and Subsetting is typically tied to the Oracle Database edition and licensing model. Technical requirements include an Oracle Database instance and sufficient system resources to handle the masking and subsetting processes. Contact Oracle sales for detailed pricing information and specific technical requirements based on your environment.
Data Anonymization Tools Comparison
| Tool | Core Features/Capabilities | User Experience/Quality ★ | Value Proposition 💰 | Target Audience 👥 | Unique Selling Points ✨ |
|---|---|---|---|---|---|
| ARX Data Anonymization Tool | k-anonymity, differential privacy, GUI | ★★★★⭐ User-friendly GUI | 💰 Free, open-source | 👥 Non-technical users, researchers | ✨ Extensive privacy models, compliance support |
| Privacera | Dynamic masking, policy management, multi-cloud | ★★★★⭐ Enterprise reliable | 💰 Enterprise priced | 👥 Large enterprises | ✨ Centralized policy management, strong integrations |
| IBM InfoSphere Optim | Advanced masking, test data mgmt, archiving | ★★★★⭐ Enterprise-grade | 💰 High licensing | 👥 Large enterprises w/ IBM stack | ✨ Strong referential integrity, lifecycle mgmt |
| Informatica Persistent Masking | Static/dynamic masking, FPE, audit trails | ★★★★⭐ Enterprise focused | 💰 Expensive licensing | 👥 Enterprises requiring compliance | ✨ Pre-built masking library, compliance features |
| Delphix Dynamic Data Platform | Virtual data copies, self-service provisioning | ★★★★⭐ Fast, automated | 💰 High investment | 👥 Enterprises needing fast data | ✨ Virtual copies reduce storage, API-driven |
| Microsoft SQL Server Masking | Built-in dynamic masking, policy-based rules | ★★★⭐ Easy integration | 💰 Included with SQL Server | 👥 SQL Server users | ✨ No app changes needed, simple setup |
| MOSTLY AI | Synthetic data with differential privacy | ★★★★⭐ High data quality | 💰 Subscription-based | 👥 Data scientists, ML teams | ✨ AI-powered synthetic data, strong privacy |
| Oracle Data Masking & Subsetting | Pre-defined masks, data subsetting, referential integrity | ★★★★⭐ Enterprise performance | 💰 High licensing cost | 👥 Oracle ecosystem users | ✨ Deep Oracle integration, enterprise security |
Choosing the Right Data Anonymization Tool
Selecting the right data anonymization tools from the many options available can feel overwhelming. This article has explored a range of solutions, from open-source tools like ARX, offering cost-effective flexibility and community support, to robust enterprise platforms like Privacera and IBM InfoSphere Optim, which deliver advanced features and scalability for large organizations. We’ve also looked at tools like Informatica Persistent Data Masking, Delphix Dynamic Data Platform, Microsoft SQL Server Data Masking, MOSTLY AI, and Oracle Data Masking and Subsetting, each with its own strengths and weaknesses. The key takeaway is that the “best” tool depends entirely on your specific needs.
The most important factors to consider when implementing data anonymization tools include the type and sensitivity of the data you’re protecting, your budget, your team’s technical expertise, and the level of compliance you need to achieve. Don’t forget to factor in ongoing maintenance and support requirements. Carefully evaluating these aspects against the capabilities of each tool will ensure a successful implementation that safeguards your sensitive data without hindering your business operations.
Successfully anonymizing data is critical, but ensuring your applications function correctly with this anonymized data is equally vital. Enhance your testing strategy by integrating a tool like GoReplay with your chosen anonymization solution. GoReplay allows you to capture and replay real-world traffic against your anonymized test environments, providing realistic and secure testing without risking sensitive production data. Learn more about how GoReplay can enhance your data anonymization workflow by visiting GoReplay.