10 Best Practices for Software Deployment in 2025
Successfully launching software into production requires more than just good code. It demands a robust, reliable, and repeatable process. In a competitive market where application uptime and user experience are paramount, the way you deploy software can be the deciding factor between seamless updates and catastrophic failures. A single flawed release can erode user trust, impact revenue, and strain development teams with stressful, all-night troubleshooting sessions. Adopting proven best practices for software deployment is not just an operational goal; it’s a strategic necessity for any modern technology organization.
This guide moves beyond theory to provide a comprehensive blueprint for building a resilient deployment pipeline. We will explore ten essential strategies that transform deployments from a source of anxiety into a routine, automated, and low-risk activity. You will gain actionable insights into implementing powerful techniques, including:
- Advanced Deployment Patterns: Master Blue-Green and Canary releases to minimize production impact.
- Infrastructure Automation: Leverage Infrastructure as Code (IaC) to create consistent and reproducible environments.
- Intelligent Quality Control: Integrate comprehensive automated testing and strict quality gates to catch issues early.
- Enhanced Reliability: Implement feature flags for controlled rollouts and establish robust monitoring and rollback plans.
Furthermore, we will demonstrate how tools like GoReplay can revolutionize your pre-deployment testing by capturing and replaying real production traffic. This allows you to validate changes against realistic user behavior, ensuring new features can handle real-world load and complexity before they ever reach your customers. By the end of this article, you’ll have a clear roadmap to refine your deployment process, enhance system stability, and deliver value to users faster and with greater confidence.
1. Continuous Integration and Continuous Deployment (CI/CD)
At the heart of modern software development lies the practice of Continuous Integration and Continuous Deployment (CI/CD). This methodology automates the process of integrating code changes from multiple developers, running a suite of automated tests, and deploying the application to various environments. By creating a robust pipeline, CI/CD minimizes manual errors, shortens release cycles, and ensures that new features reach users faster and more reliably.
Companies like Netflix and Amazon have famously leveraged CI/CD to achieve thousands of deployments per day, demonstrating its power to scale operations and accelerate innovation. This approach is fundamental to a high-velocity development culture, making it an essential best practice for software deployment. The core principle is to make deployments a routine, low-risk event rather than a dreaded, high-stakes affair.
Implementing a CI/CD Pipeline
To adopt this practice, start with a simple pipeline and incrementally add complexity. A foundational CI/CD workflow follows a clear, automated sequence.
This infographic illustrates the core stages of a typical CI/CD process flow.
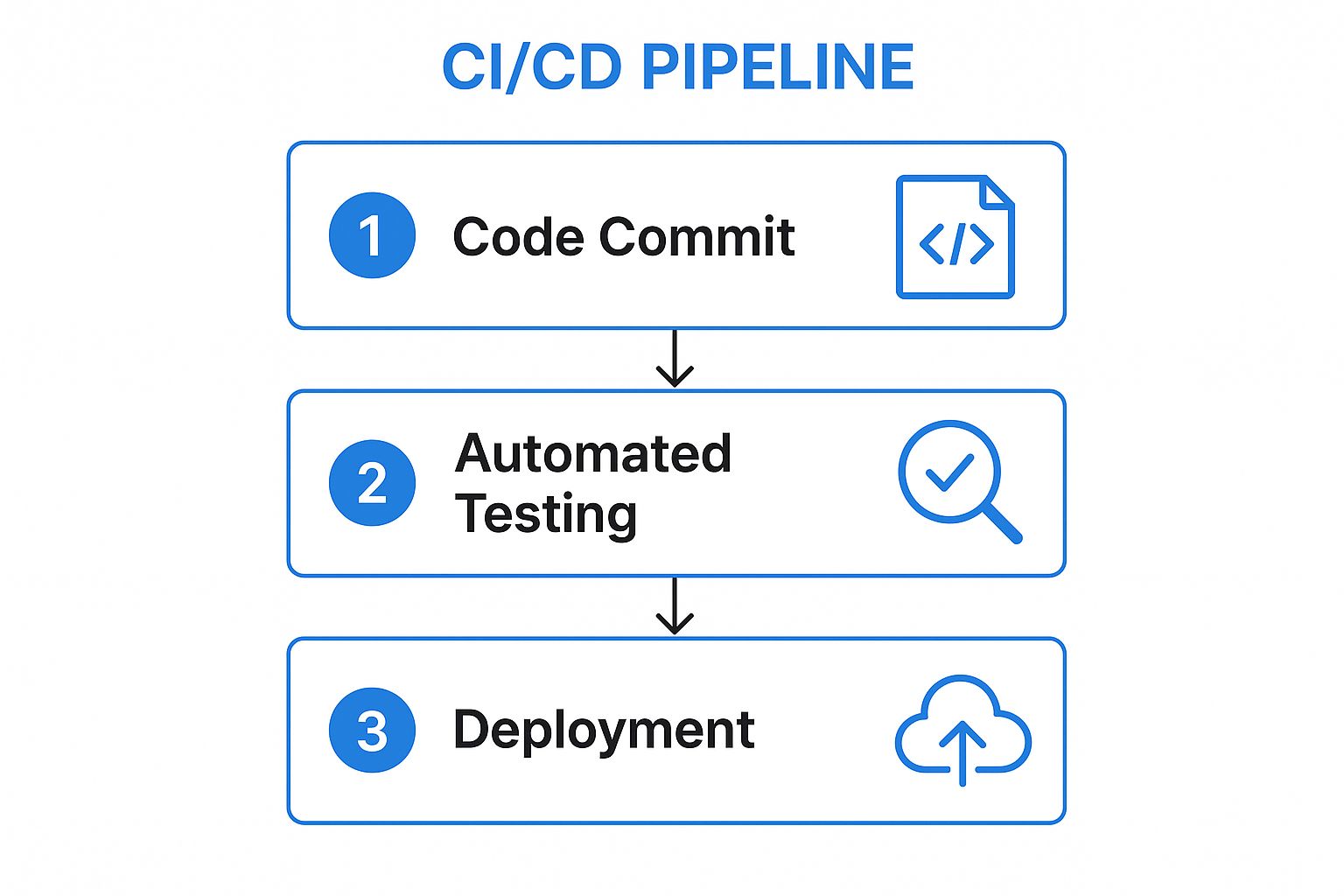
As shown, the process moves seamlessly from a developer’s code commit to automated testing and finally to deployment, creating a rapid feedback loop.
Key Implementation Tips
- Start Small: Begin with a basic pipeline that only builds and tests your code. Gradually add deployment stages for different environments (e.g., staging, production).
- Comprehensive Automated Testing: Your pipeline’s reliability depends on the quality of your tests. Implement unit, integration, and end-to-end tests to catch bugs early.
- Use Feature Flags: Decouple deployment from release by using feature flags. This allows you to deploy new code to production disabled by default, enabling it for specific users or a percentage of traffic when you’re confident it’s stable.
- Ensure Environment Parity: Keep your development, staging, and production environments as similar as possible to avoid “it works on my machine” issues. Use tools like Docker to containerize your application and ensure consistency across all stages.
2. Blue-Green Deployment
Blue-green deployment is a powerful strategy designed to eliminate downtime and reduce deployment risk. It involves maintaining two identical, isolated production environments, aptly named “Blue” and “Green.” At any given time, only one environment (e.g., Blue) is live and handling all user traffic. The new version of the application is deployed to the idle environment (Green), where it can be thoroughly tested in a production-like setting without impacting users.

This method transforms deployments into a non-event. Once the new version in the Green environment is verified and deemed stable, a simple router switch redirects all live traffic from Blue to Green. The old Blue environment is kept on standby for a quick and easy rollback if any issues arise. This technique is a cornerstone of reliable deployment practices, used by companies like Netflix for their streaming services and Adobe for their Creative Cloud platform.
Implementing Blue-Green Deployments
To adopt this practice, you must focus on automation and robust health checks to make the traffic switch seamless and reliable. The core idea is to make the transition between environments instantaneous from the user’s perspective.
This video from IBM Cloud provides a concise explanation of how Blue-Green deployments work in practice.
As illustrated, the traffic switch is the critical point, making the new version instantly live while providing an immediate fallback plan.
Key Implementation Tips
- Automate the Switch: The process of switching traffic from the Blue to the Green environment should be fully automated. Use a load balancer or router script to make the change instantaneous and minimize the potential for human error.
- Implement Robust Health Checks: Before flipping the switch, run a comprehensive suite of health checks and automated smoke tests on the new (Green) environment. These checks must validate critical application functionalities and integrations.
- Plan Database Migration Strategies: Managing database changes is the most complex part of blue-green deployments. Consider using backward-compatible schema changes or a shared, highly available database to ensure both environments can function during the transition.
- Monitor Both Environments: During and after the switch, closely monitor the performance and error rates of both environments. This ensures you can quickly detect issues with the new version and roll back to the stable, old environment if necessary.
3. Canary Deployments
Canary deployment is a progressive delivery strategy where a new software version is rolled out to a small subset of real users before a full release. This technique, named after the canaries used in coal mines to detect toxic gases, allows teams to test changes in a live production environment with minimal risk. By exposing the new version to a small percentage of traffic, you can monitor its performance and user impact before making it available to everyone.

Tech giants like Google and Facebook rely heavily on this method. Google canary tests updates for critical services like Search and Gmail, while Facebook rolls out new features to a small percentage of users first. This approach is a cornerstone of reliable, large-scale software deployment, enabling teams to gather real-world data and validate stability confidently. It minimizes the blast radius of potential issues, making it one of the most effective best practices for software deployment.
Implementing Canary Deployments
Adopting canary deployments involves routing a fraction of your production traffic to the new version while the majority continues to use the stable version. This parallel run allows for direct comparison and quick reversion if problems arise.
The core idea is to de-risk the deployment process. You can start with a very small user group, such as internal teams or beta testers, and gradually increase the traffic to the new version as confidence in its stability grows. This incremental exposure is key to catching subtle bugs that may not appear in staging environments.
Key Implementation Tips
- Define Clear Metrics: Before starting, establish clear success metrics. Key performance indicators (KPIs) like error rates, CPU/memory usage, and user engagement will help you objectively determine if the canary version is performing as expected.
- Automate Monitoring and Alerting: Implement robust, automated monitoring to track the health of both the canary and stable versions. Set up alerts to notify the team immediately if the canary’s performance degrades.
- Plan for Quick Rollbacks: Have an automated rollback plan ready. If the canary release shows signs of trouble, you must be able to instantly divert all traffic back to the stable version to minimize user impact.
- Use Feature Flags: Combine canary deployments with feature flags for even more granular control. This allows you to enable or disable specific features within the canary release without needing a full redeployment.
4. Infrastructure as Code (IaC)
A pivotal shift in modern operations, Infrastructure as Code (IaC) is the practice of managing and provisioning computing infrastructure through machine-readable definition files. Instead of relying on manual hardware configuration or interactive tools, IaC treats infrastructure provisioning just like application code. This allows teams to apply software development best practices like version control, code review, and automated testing to their infrastructure, dramatically improving consistency and reliability.
Companies like Spotify have embraced IaC to manage complex multi-cloud environments, while Capital One uses it to ensure compliance and security across its vast AWS footprint. By codifying infrastructure, organizations can eliminate configuration drift, automate environment creation, and achieve identical setups from development to production. This makes IaC an indispensable component of any modern software deployment strategy, turning infrastructure management from a manual bottleneck into an automated, scalable process.
Implementing Infrastructure as Code
Adopting IaC involves choosing a tool and gradually migrating your existing manual processes to a code-based workflow. The goal is to create a single source of truth for your infrastructure that is version-controlled and can be automatically applied.
This approach ensures that every change is deliberate, reviewed, and reproducible, forming a solid foundation for your deployment pipeline.
Key Implementation Tips
- Version Control Everything: Store all your infrastructure code (e.g., Terraform, CloudFormation, or Ansible files) in a version control system like Git. This provides a full audit trail and the ability to roll back changes.
- Embrace Modularity: Follow the Don’t Repeat Yourself (DRY) principle by creating reusable modules for common infrastructure components like virtual networks or server clusters. This simplifies management and ensures consistency.
- Test Your Infrastructure Code: Implement a testing strategy for your IaC. Use tools to lint your code for syntax errors, validate configurations, and even run integration tests in a temporary environment before applying changes to production.
- Manage Secrets Securely: Never hardcode secrets like API keys or passwords in your IaC files. Use a dedicated secret management tool such as HashiCorp Vault or AWS Secrets Manager to inject credentials securely at runtime.
5. Automated Testing and Quality Gates
A deployment pipeline is only as reliable as the code it promotes. This is where automated testing and quality gates become indispensable best practices for software deployment. This approach involves embedding comprehensive, automated test suites directly into the CI/CD pipeline, creating mandatory checkpoints that code must pass before advancing to the next stage. These gates ensure that only high-quality, stable, and secure code reaches production.
Top tech companies build their deployment strategies around this principle. For instance, Google often requires extensive test coverage for its critical services, while Microsoft heavily integrates automated quality gates within its Azure DevOps pipelines. This practice transforms testing from a manual, end-of-cycle activity into a continuous, automated process that safeguards production environments and maintains user trust.
Implementing a Robust Testing Strategy
A successful implementation relies on a layered testing approach and clear, non-negotiable quality standards. The goal is to catch issues as early and efficiently as possible.
This multi-faceted approach ensures that different aspects of the application, from individual functions to the system as a whole, are validated before release. By setting these gates, you create a system that automatically rejects builds that fail to meet predefined standards for performance, security, or functionality, preventing regressions and reducing risk.
Key Implementation Tips
- Implement the Testing Pyramid: Structure your tests according to the testing pyramid model. Focus on a large base of fast, cheap unit tests, a smaller layer of integration tests, and a minimal number of slow, expensive end-to-end tests.
- Use Parallel Test Execution: Drastically reduce pipeline wait times by running tests in parallel. Most modern CI/CD tools and test frameworks support this, allowing you to get feedback faster.
- Set Realistic Quality Thresholds: Define clear, achievable quality gates. This could include code coverage minimums (e.g., 80%), performance benchmarks, or zero critical security vulnerabilities. These thresholds should be non-negotiable.
- Invest in Test Data Management: High-quality testing requires realistic and consistent test data. Develop a strategy for generating, managing, and cleaning test data to ensure your automated tests are meaningful and reliable. The game-changing benefits of automated testing are often directly tied to the quality of the data used.
6. Feature Flags and Toggle Management
Feature flags, also known as feature toggles, are a powerful technique that decouples code deployment from feature release. This practice allows teams to modify system behavior by enabling or disabling features in a live environment without deploying new code. This separation is crucial for modern, agile development, as it minimizes risk, enables experimentation, and provides granular control over the user experience, transforming deployments into non-events.
This infographic illustrates how feature flags provide granular control over feature releases.

Tech giants like Facebook and Netflix rely heavily on feature flags. Facebook uses them for gradual rollouts to its massive user base, while Netflix employs them for safe experimentation with new algorithms and UI changes. This methodology is one of the most effective best practices for software deployment when aiming for continuous delivery and operational flexibility.
Implementing Feature Flags
To get started, you can use dedicated feature management platforms like LaunchDarkly or build a simple internal solution. The key is to wrap new functionality in conditional logic that checks the state of a flag.
Key Implementation Tips
- Establish a Flag Lifecycle: Define a clear process for creating, managing, and removing flags. Stale or obsolete flags create technical debt and can complicate your codebase.
- Use Consistent Naming Conventions: Adopt a standardized naming scheme for flags (e.g.,
[component]-[feature]-[purpose]) to make them easily identifiable and maintainable. - Implement Access Controls: Control who can modify flags. Limit access to production flags to prevent accidental changes that could impact users.
- Monitor Flag Performance: Track the performance impact of features enabled by flags. This helps identify any latency or resource consumption issues before a full rollout.
- Clean Up Obsolete Flags: Regularly audit and remove flags for features that are fully rolled out or abandoned. This keeps your code clean and reduces complexity.
7. Monitoring and Observability
Once a deployment is live, the work is far from over. Effective monitoring and observability are critical best practices for software deployment that provide deep insights into how your application performs in a live environment. This practice involves collecting, aggregating, and analyzing metrics, logs, and traces to understand system health, identify performance bottlenecks, and detect anomalies before they impact users.
Leading tech companies demonstrate the immense value of this approach. Shopify, for instance, relies on sophisticated monitoring to maintain 99.99% uptime during high-stakes events like Black Friday, while Uber’s observability platform processes millions of events per second to keep its global services running smoothly. This proactive stance transforms operations from reactive firefighting to data-driven, preemptive problem-solving.
Implementing a Monitoring and Observability Strategy
A successful strategy moves beyond simple server health checks to a holistic view of the application and business. It requires integrating the right tools and focusing on metrics that truly matter.
Modern observability is built on three pillars: metrics (numeric data), logs (event records), and traces (request lifecycles). When combined, they provide a complete picture of your system’s behavior, allowing teams to quickly diagnose and resolve complex issues, especially in distributed microservices architectures. This comprehensive view is essential for maintaining service reliability and a positive user experience.
Key Implementation Tips
- Focus on Business-Centric Metrics: Track technical metrics like CPU and memory usage, but prioritize business KPIs like conversion rates, user engagement, and transaction times. This aligns technical performance with business outcomes.
- Implement Smart Alerting: Avoid alert fatigue by setting meaningful thresholds and severity levels. Alerts should be actionable and directed to the right team, ensuring rapid response without unnecessary noise.
- Use Distributed Tracing for Microservices: In complex systems, tracing helps visualize the entire path of a user request as it travels through different services. Tools like Jaeger or Datadog are invaluable for pinpointing failures and latency issues.
- Create Role-Specific Dashboards: Build customized dashboards with tools like Grafana for different stakeholders. Engineers need granular system data, while business leaders need high-level performance overviews.
- Centralize Log Management: Aggregate logs from all services into a centralized platform like the ELK Stack or Splunk. This enables powerful searching, analysis, and correlation, which is crucial for troubleshooting production incidents.
8. Rollback and Recovery Strategies
No matter how thorough your testing, deployments can sometimes fail. A critical best practice for software deployment is having robust rollback and recovery strategies. These are predefined, automated procedures that allow teams to swiftly revert a problematic deployment to a previously stable state, drastically minimizing downtime and user impact. The goal is to make failure a non-event by ensuring a rapid and reliable path back to safety.
Companies known for their operational excellence, like Amazon and Slack, have deeply integrated automated rollback capabilities into their deployment systems. This practice is a cornerstone of Site Reliability Engineering (SRE), treating operational reliability as a software engineering problem. By preparing for failure, you build resilience directly into your deployment lifecycle, turning potential catastrophes into minor, manageable incidents.
Implementing Rollback and Recovery
Effective rollback strategies require more than just redeploying an old artifact; they involve a holistic plan that considers the entire application state, including databases and configurations. Automation is key to executing these plans quickly and without human error under pressure.
These strategies are your ultimate safety net, ensuring that if a deployment introduces critical bugs or performance degradation, you can restore service with minimal disruption.
Key Implementation Tips
- Test Rollback Procedures Regularly: Don’t assume your rollback plan works. Regularly test the entire rollback process in a staging environment to ensure it functions as expected and your team knows how to execute it.
- Implement Automatic Triggers: Use monitoring and alerting to create automatic rollback triggers. For example, if error rates or latency spike beyond a certain threshold post-deployment, a circuit breaker can automatically initiate the rollback process without manual intervention.
- Plan for Database Rollbacks: Reverting application code is often the easy part. You must also have a clear strategy for database changes, such as backward-compatible migrations or procedures to revert schema and data modifications safely.
- Document Everything: Maintain clear, accessible documentation for all rollback procedures. During an incident, teams need a step-by-step guide they can follow without confusion, ensuring a calm and efficient response.
9. Environment Parity and Configuration Management
The infamous “it works on my machine” problem is a classic source of deployment failures. Environment parity directly addresses this by ensuring that development, staging, and production environments are as identical as possible. This practice, combined with robust configuration management, isolates environment-specific settings from the core application code, drastically reducing unexpected behavior and deployment surprises.
This principle is a cornerstone of Heroku’s influential 12-Factor App methodology, which advocates for strict separation between code and configuration. By treating environments as disposable, consistent, and easily reproducible, teams can deploy with much higher confidence. This approach minimizes bugs that only appear in production and makes troubleshooting far more predictable, solidifying its place as one of the best practices for software deployment.
Implementing Environment Parity
Achieving true parity requires a deliberate strategy to manage both the environment’s structure and its configuration. The goal is to eliminate drift and ensure that what you test is exactly what you deploy. This involves automating the creation and management of your environments and externalizing all configuration details.
Key Implementation Tips
- Use Containerization: Tools like Docker are essential for achieving environment parity. They package your application and its dependencies into a single, portable container that runs identically across development, staging, and production.
- Implement Configuration as Code (CaC): Use tools like Terraform or Ansible to define your infrastructure programmatically. This ensures environments are provisioned consistently and any changes are version-controlled and auditable.
- Store Config in the Environment: Never hardcode configuration values like database credentials or API keys in your code. Instead, use environment variables. Tools like Kubernetes ConfigMaps and Secrets or HashiCorp Vault are designed specifically for managing this externally.
- Automate Environment Provisioning: Create fully automated scripts to build your environments from scratch. This allows you to quickly spin up a new, clean staging environment for testing a feature branch, ensuring it perfectly mirrors production.
- Regularly Audit for Differences: Continuously monitor and audit your environments to detect and correct any configuration drift. Automated checks can compare settings across stages and alert you to inconsistencies before they cause issues.
10. Security Integration in Deployment Pipeline
Integrating security directly into the deployment pipeline, a practice known as DevSecOps, transforms security from a final checkpoint into an ongoing, automated process. This approach embeds security controls, scanning, and testing throughout the software development lifecycle. By making security an integral part of development and deployment, teams can identify and remediate vulnerabilities early, reducing risk and avoiding costly fixes post-release.
Tech giants like Google and Microsoft have championed this model by embedding automated security gates directly into their CI/CD pipelines. This ensures that every code change is scrutinized for potential threats before it reaches production. Shifting security “left” makes secure software deployment a shared responsibility, fostering a culture where every developer is a security advocate.
Implementing DevSecOps
Adopting DevSecOps involves integrating security tools and practices at various stages of your existing pipeline. The goal is to automate security checks so they run seamlessly alongside your build and test jobs, providing immediate feedback to developers. This proactive stance is a cornerstone of modern, resilient software deployment practices.
A successful implementation means security scans are as routine as unit tests. For instance, Static Application Security Testing (SAST) can scan source code upon commit, while Dynamic Application Security Testing (DAST) can test the running application in a staging environment. To learn more about innovative approaches, you can explore how integrated testing can overcome traditional DAST challenges.
Key Implementation Tips
- Scan at Multiple Stages: Implement various security scanning tools throughout the pipeline. Use SAST for early code analysis, Software Composition Analysis (SCA) to check for vulnerable dependencies, and DAST for testing the application in a runtime environment.
- Automate Secret Detection: Integrate tools like Git-secrets or TruffleHog to automatically scan code repositories for inadvertently committed secrets like API keys and passwords.
- Implement Strict Access Controls: Use the principle of least privilege for pipeline access. Ensure that only authorized personnel and automated systems can trigger deployments or modify pipeline configurations.
- Keep Security Tools Updated: Security threats evolve constantly. Regularly update your scanning tools, vulnerability databases, and rule sets to ensure you are protected against the latest known exploits.
- Train Your Teams: Equip your development and operations teams with ongoing security training. A knowledgeable team is your first and best line of defense against security threats.
Best Practices Deployment Comparison
| Technique | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Continuous Integration & Deployment (CI/CD) | Medium-High: Setup pipelines, tests | Medium-High: Infrastructure, test coverage | Rapid, reliable deployments; early bug detection | Teams needing fast, frequent releases | Faster cycles, reduced errors, early feedback |
| Blue-Green Deployment | High: Duplicate environments, sync | High: Double infrastructure | Zero-downtime deployments; instant rollback | Critical systems requiring high availability | Zero downtime, easy rollback, risk reduction |
| Canary Deployments | High: Traffic management, monitoring | Medium-High: Monitoring tools | Gradual rollouts; real user feedback | Feature testing with limited risk exposure | Reduced failure impact, data-driven releases |
| Infrastructure as Code (IaC) | Medium-High: Tool learning curve | Medium: Automation tools | Consistent environments; faster provisioning | Managing infrastructure at scale | Consistency, reduced manual errors, automation |
| Automated Testing & Quality Gates | High: Test creation & maintenance | Medium-High: Test environments | Better code quality; early bug detection | Ensuring code quality before deployment | Early bugs, consistent quality, faster feedback |
| Feature Flags & Toggle Management | Medium: Code complexity increase | Low-Medium: Flag infrastructure | Safer releases; control over feature exposure | Controlled feature releases, experiments | Safer releases, fast disable, A/B testing |
| Monitoring and Observability | High: Complex setup & maintenance | High: Data storage, processing | Faster issue detection; system health insight | Operational monitoring & incident response | Proactive detection, improved UX, data-driven decisions |
| Rollback and Recovery Strategies | Medium-High: Automation & planning | Medium: Testing & automation tools | Quick recovery; minimal downtime | Systems needing safe failure handling | Rapid recovery, reduced MTTR, increased confidence |
| Environment Parity & Config Mgmt | Medium: Configuration discipline | Medium: Tools for management | Consistent deployments; fewer environment bugs | Multi-stage environments needing consistency | Reduced bugs, consistent behavior, better security |
| Security Integration in Pipeline | High: Security tools & policies | Medium-High: Security scanning tools | Early vulnerability detection; compliance | Secure deployments integrating DevSecOps | Early security fixes, automated compliance, stronger posture |
From Theory to Practice: Building Your Resilient Deployment Strategy
Navigating the landscape of modern software delivery requires more than just good code; it demands a robust, resilient, and repeatable deployment process. Throughout this guide, we’ve explored the ten pillars that form the foundation of elite software deployment. From the automation engine of CI/CD to the surgical precision of Canary Deployments and the proactive insight of comprehensive observability, each practice represents a critical step toward minimizing risk and maximizing value. The journey from a manual, error-prone process to a sophisticated, automated pipeline is not merely an operational upgrade. It is a fundamental transformation that directly impacts your team’s velocity, your product’s reliability, and your organization’s ability to innovate and compete.
Mastering these best practices for software deployment is about building a system of interlocking gears. Your Infrastructure as Code (IaC) ensures that your environments are consistent, which in turn makes your Blue-Green deployments more reliable. Automated testing and quality gates act as the essential safety net for your CI/CD pipeline, catching issues before they impact users. Similarly, feature flags provide the granular control needed to safely roll out new functionality, while robust rollback strategies offer a lifeline when the unexpected occurs. It’s the synergy between these components that creates a truly resilient deployment strategy.
Your Actionable Roadmap to Deployment Excellence
Moving from theoretical knowledge to practical implementation is the most crucial step. To help you begin this journey, here are your immediate next steps:
- Conduct a Deployment Audit: Start by evaluating your current process against the ten practices discussed. Identify the biggest gaps and pain points. Are you still deploying manually? Is your testing comprehensive enough? Do you have a clear rollback plan? This audit will provide a clear, prioritized list of areas for improvement.
- Implement One Small Change: Don’t try to overhaul everything at once. Pick one high-impact, low-effort practice to implement first. This could be introducing a basic CI pipeline for a single service, containerizing an application with Docker to improve environment parity, or adding more detailed logging to enhance observability. Early wins build momentum and demonstrate value.
- Embrace ‘As Code’ Philosophies: The shift toward defining infrastructure (IaC) and pipelines (pipelines-as-code) is a powerful one. It brings version control, peer review, and automation to the core of your operations. Prioritize moving manual configurations into code-based, versioned artifacts to create a single source of truth.
The ultimate goal is to cultivate a culture of quality and continuous improvement. Adopting these best practices for software deployment empowers your teams to release software with confidence, knowing that safety nets are in place and that every step is automated, tested, and observable. This confidence translates into faster feedback loops, more frequent releases, and a superior experience for your end-users. You move from a state of fearing deployments to one where they are routine, predictable, and even boring, which is the hallmark of a truly mature DevOps organization. By investing in these principles, you are not just optimizing a technical process; you are building a strategic advantage that allows your business to adapt and thrive in a fast-paced digital world.
Ready to supercharge your testing and validate deployments with real user traffic? GoReplay allows you to capture and replay your production traffic in development and staging environments, providing the ultimate confidence that your changes are safe and performant. Eliminate deployment anxiety by testing against real-world scenarios with GoReplay.